

Czym jest code review
Jeśli nigdy nie słyszałeś o code review, jest to proces, w którym pokazujesz napisany przez siebie kod komuś innemu z zespołu, zanim trafi on na produkcję, czyli do działającej aplikacji.
W nowoczesnej inżynierii oprogramowania code review przestało być jedynie opcjonalnym krokiem - stało się wręcz filarem, który wzmacnia jakość, bezpieczeństwo, a dodatkowo redukuje koszty.
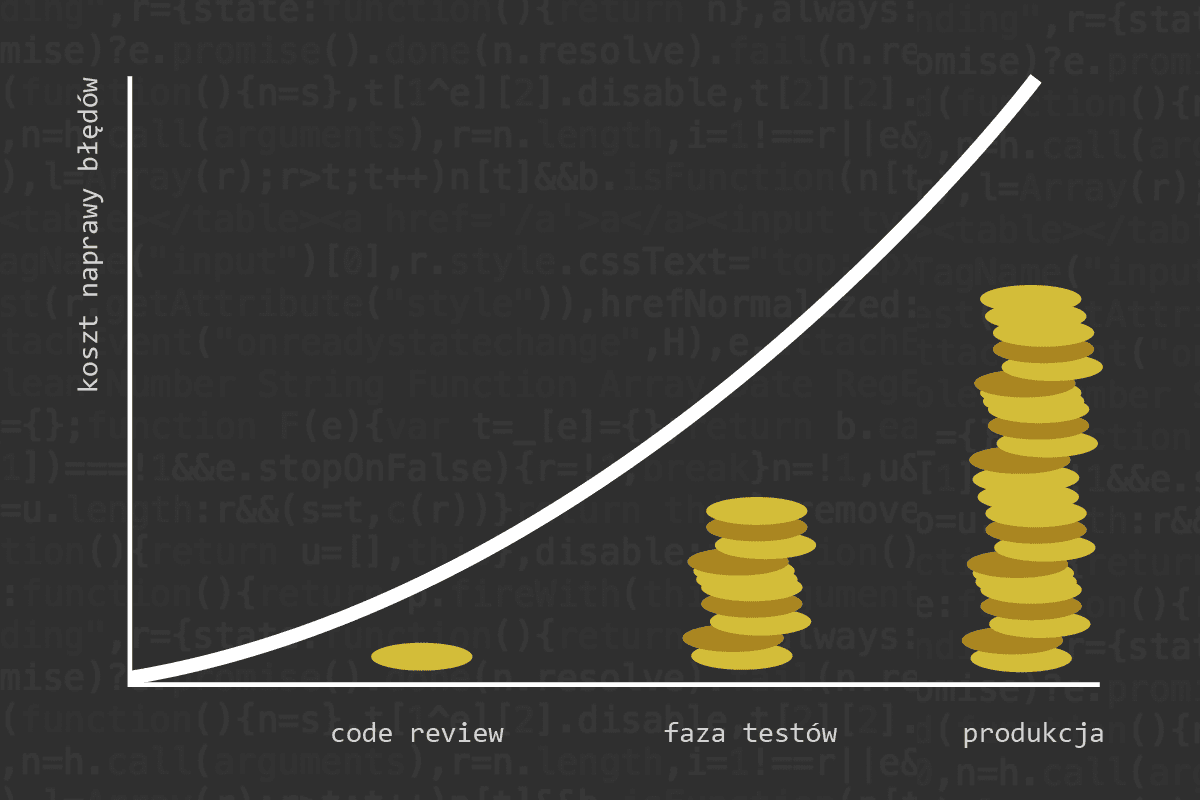
Głównym celem code review jest poprawa jakości kodu poprzez wczesne wykrywanie błędów. Koszt naprawy błędu rośnie wykładniczo w miarę jak oprogramowanie przechodzi przez kolejne cykle swojego życia. Błąd wykryty na etapie code review jest wielokrotnie tańszy w naprawie niż ten sam błąd znaleziony w środowisku produkcyjnym przez klienta.
Rola recenzującego nie polega jedynie na znajdowaniu błędów. Jest on jak mechanik w zespole wyścigowym: nie tylko naprawia to, co się zepsuło, ale dba też o ogólny stan techniczny bolidu, by dobrze służył przez cały sezon. Wymaga to zastanowienia, czy kod będzie zrozumiały, łatwy w utrzymaniu i bezpieczny w przyszłości?
Co wziąć pod uwagę podczas code review?
1. Poprawność i funkcjonalność kodu
Podstawową sprawą jest zweryfikowanie, czy kod realizuje to, co obiecuje autor pull requesta w jego opisie. To pierwsza rzecz, jaka Cię będzie interesowała. Nie zakładaj, że testował on każdy przypadek. Dobrze sprawdzić szczególnie te najbardziej “podstępne” edge case’y.
Jako recenzujący szukaj więc słabości. Sprawdzaj na przykład, jak kod zachowa się dla pustych danych, wartości null, nieprawidłowych typów czy warunków granicznych (np. błędy off-by-one).
W przypadku kodu wielowątkowego, warto mentalnie prześledzić ścieżki wykonania: jak wątki mogą sobie wejść w drogę. Zastanów się, czy jest ryzyko, że się wzajemnie zablokują (deadlock) albo zaczną "ścigać" do tych samych danych (race condition). Warto to robić, bo automatyczne testy są na takie błędy często ślepe.
2. Czytelność, styl i utrzymywalność
Kod jest pisany przede wszystkim dla ludzi, a dopiero w drugiej kolejności dla maszyn. Więc jako recenzujący musisz ocenić, czy kod jest jasny, zrozumiały i łatwy do utrzymania. W związku z tym powinien on posiadac pewne cechy:
Dobre nazewnictwo: jednoznaczne, opisowe nazwy zmiennych, funkcji i klas. Semantycznie mętne nazwy, takie jak
data,volumeczyt, powinny zapalić czerwoną lampkę w Twojej głowie.Modularność: kod podzielony na mniejsze funkcje lub metody. Duże, monolityczne funkcje są trudne do zrozumienia, testowania i modyfikacji.
Brak "magii": nie powinno być żadnych magicznych liczb czy tajemniczych stringów. Należy je zastąpić nazwanymi stałymi, aby poprawić czytelność i ułatwić przyszłe zmiany (więcej o nazewnictwie przeczytasz tutaj).
Spójność stylu: kod musi być zgodny z ustalonymi w projekcie konwencjami formatowania i stylu. Mimo że automatyczne narzędzia (lintery) wyłapują większość błędów, ludzkie oko może wychwycić inne niespójności w stosowanych wzorcach. Nie chodzi tylko o ładny wygląd, ale, by każdy w zespole od razu wiedział, czego się spodziewać.
3. Architekturę i projekt
Nowy kod musi harmonijnie wpisywać się w istniejącą strukturę projektu, a nie działać wbrew niej. Warto więc zweryfikować niektóre sprawy:
Czy nowe rozwiązanie zachowuje spójność z istniejącą architekturą projektu? Nie powinno ono wprowadzać sprzecznych wzorców czy walczyć z frameworkiem. Przykład? Jeśli w projekcie używamy
async/await, nie możemy nagle wstawiać callbacków lub.then().Czy kod jest zgodny z podstawowymi zasadami projektowymi, jak np. Zasada Jednej Odpowiedzialności (Single Responsibility Principle), zgodnie z którą klasa lub funkcja powinna robić jedną rzecz i robić ją dobrze. Bądź wyczulony na zduplikowaną logikę. Jeśli np. ten sam blok kodu pojawia się w wielu miejscach, jest to sygnał do wyodrębnienia go do wspólnej funkcji lub serwisu.
Czy ważne decyzje projektowe są udokumentowane: w opisie PR lub w komentarzach w kodzie? Jako recenzujący chciałbyś chociażby zrozumieć kompromisy, na które zdecydował się autor.
4. Bezpieczeństwo i odporność na ataki
Pamiętaj, że każdy fragment kodu, który przetwarza dane z zewnętrznych źródeł, jest potencjalnym wektorem ataku. Dlatego też:
Wszystkie dane wejściowe (od użytkowników, z API, z plików) muszą być traktowane jako niezaufane. Sprawdź, czy są one odpowiednio walidowane i oczyszczane (sanitized), by zapobiec popularnym podatnościom, takim jak SQL Injection i Cross-Site Scripting (piszemy o tym w innym artykule: tutaj). To ważne, bo w praktyce właśnie te oczywiste metody najczęściej są wykorzystywane przez atakujących.
Kod musi obsługiwać potencjalne błędy i wyjątki. Nie powinien ulegać awarii w przypadku nieoczekiwanych danych. Zweryfikuj, czy bloki try-catch są używane prawidłowo i czy komunikaty o błędach są jasne i użyteczne, a jednocześnie nie ujawniają wrażliwych informacji. W końcu to użytkownik ma dostać informację, która mu pomoże, a nie potencjalny atakujący.
Kwestia danych wrażliwych - żadnych zaszytych na stałe kluczy API czy haseł. Sprawdź, czy są one zarządzane przez bezpieczne mechanizmy konfiguracyjne albo dedykowane narzędzia. To niby banał, ale wciąż często spotykany błąd.
5. Wydajność
Tutaj celem jest identyfikacja realnych wąskich gardeł, które mogą wpłynąć na doświadczenie użytkownika. Powinieneś przyjrzeć się:
Czy wybrany algorytm jest odpowiedni do oczekiwanej skali problemu? Szukaj nieefektywnych operacji, takich jak zagnieżdżone pętle na dużych zbiorach danych (gdzie mapa czy tablica haszująca, o której też już pisaliśmy, byłyby znacznie wydajniejsze).
Czy nie ma potencjalnych wycieków pamięci, niepotrzebnych zapytań do bazy danych wewnątrz pętli albo nieefektywnej alokacji zasobów.
Zgłaszaj problemy z wydajnością tylko wtedy, gdy jest prawdopodobne, że będą miały one realny wpływ na działanie systemu. W razie wątpliwości, najlepszą praktyką jest pozostawienie komentarza z prośbą o wyjaśnienie albo sugestią monitorowania w przyszłości, zamiast kategorycznego żądania optymalizacji.
6. Jakość testów
Testy są integralną częścią zmiany i muszą być recenzowane z taką samą starannością jak kod produkcyjny.
Musisz patrzeć dalej niż tylko na procentowe pokrycie kodu testami. Same testy wymagają oceny jakościowej.
Czy testy mają dobre nazwy i są łatwe do zrozumienia? Nazwa testu powinna jasno komunikować, jaki scenariusz jest testowany i jaki będzie oczekiwany rezultat.
Czy obejmują one szczęśliwą ścieżkę (gdy wszystko działa, jak należy), przypadki brzegowe i warunki błędów? Czy sprawdzają właściwe rzeczy? Dobry test nie przejdzie, jeśli kod zawiera błędy, i powiedzie się, gdy wszystko działa poprawnie.
Czy w kodzie nie ma przestarzałych lub pustych testów, które należy usunąć?
Poszczególne części code review są ze sobą powiązane i często wymagają kompromisów. Na przykład jakiś bardzo wydajny algorytm może być mniej czytelny. Doskonałe rozwiązanie architektoniczne może może spowolnić działanie systemu albo wymagać więcej zasobów. Twoim zadaniem jako recenzenta nie jest tylko odhaczenie checklisty, ale zainicjowanie rozmowy na temat tych kompromisów projektowych. Bo celem jest znalezienie najbardziej odpowiedniego rozwiązania dla konkretnego problemu i upewnienie się, że uzasadnienie tego wyboru zostało udokumentowane. Dzięki temu inni w zespole, albo Ty sam za pół roku, zrozumieją, dlaczego taka decyzja została podjęta.
Jak konstruktywnie przekazać krytykę
Sposób, w jaki przekazywana będzie informacja zwrotna, także jest istotny. Komentarze to narzędzie, które pomaga przekazywać wiedzę, a jednocześnie minimalizować niepotrzebne tarcia. Jak w każdej interakcji międzyludzkiej, nawet najbardziej konstruktywny feedback może czasem wywołać reakcję obronną. A przecież chcemy tworzyć zdrowy i efektywny proces... W jaki więc sposób możemy minimalizować ten efekt?
Krytykuj kod, nie programistę. To najważniejsza zasada. Wszelkie uwagi muszą być skierowane w kierunku kodu, a nie osoby, która go napisała. Nie pisz: Dlaczego nie wydzieliłeś tego do osobnej funkcji? Znowu duplikujesz kod. Taki komentarz brzmi jak oskarżenie i może sugerować lenistwo lub brak umiejętności autora. Lepiej będzie to ująć w taki sposób: Zauważyłem, że ta logika walidacji pojawia się też w innym miejscu. Może warto byłoby wyciągnąć ją do wspólnej, reużywalnej funkcji? Ułatwi nam to wprowadzanie zmian w przyszłości. Ten komentarz skupia się na kodzie, sugeruje konkretne rozwiązanie i wyjaśnia korzyść z takiej zmiany, otwierając pole do dyskusji.
Miej świadomość błędów poznawczych. Recenzujący, jak wszyscy ludzie, są na nie podatni. Jednym z najczęstszych w code review jest błąd potwierdzenia (confirmation bias). W skrócie to tendencja naszego mózgu do szukania dowodów, które potwierdzają to, w co już wierzymy, i ignorowania tych, które temu przeczą. To takie mentalne klapki na oczach, które sprawiają, że czujemy, że mamy rację. W praktyce polega to na ocenianiu kodu przez pryzmat tego, kto go napisał, a nie tego, jaki ten jest on naprawdę.
Przykład:
Wyobraź sobie doświadczoną programistkę Marię i juniora Romka, który właśnie otrzymał nowe zadanie. Maria spodziewa się, że kod Romka będzie zawierał błędy i proste rozwiązania. Ale Romek zresearchował głębiej problem, nad którym pracuje, i zamiast prostej pętli, stworzył bardziej złożony, ale znacznie wydajniejszy algorytm. Wpadając w pułapkę confirmation bias Maria szuka dowodów na to, że kod jest zły. Widząc złożoność, ignoruje jej cel (wydajność) i skupia się na tym, co potwierdza jej tezę: że junior przekombinował. Jej komentarz może brzmieć: Ten kod jest zbyt skomplikowany. Wystarczyłaby prosta pętla. Gdyby Maria była świadoma swojego uprzedzenia zadałaby sobie pytanie, dlaczego ten kod wygląda inaczej, niż się spodziewała. Wtedy może zauważyłaby, że Romek rozwiązał problem wydajnościowy, o którym ona nie pomyślała...
Jak pisać komentarze, które pomagają
Opanowanie sztuki formułowania komentarzy jest bardzo ważne dla sukcesu code review. Poniżej kilka przykładów i technik, które pomagają przekształcić krytykę w wartościowy dialog.
Komentarz nieefektywny | Dobra alternatywa |
|---|---|
To jest źle. To się zepsuje. | Obawiam się, że w tym miejscu może wystąpić race condition. Czy rozważaliśmy dodanie tutaj blokady? |
Użyj pętli | Może warto użyć pętli |
Ta klasa jest bez sensu. | Mam problem ze zrozumieniem odpowiedzialności tej klasy. Moglibyśmy ją podzielić na mniejsze, bardziej wyspecjalizowane komponenty? |
Nie rozumiem tego kodu. | Możesz wyjaśnić, jaka jest intencja tego fragmentu? Może warto dodać komentarz na przyszłość. |
Gdzie są testy? | Ta logika wydaje się dość złożona. Dodanie kilku testów jednostkowych dla edge case'ów mogłoby zwiększyć pewność co do jej poprawności. |
Formułuj uwagi jako pytania lub sugestie, a nie rozkazy. To otwiera dialog i uwzględnia samodzielność autora.
Wyjaśniaj dlaczego. Nigdy nie stwierdzaj po prostu, że coś jest nie tak. Zawsze podawaj powody swojej sugestii, wskazując argumenty.
Pisz opinie z własnej perspektywy. To sprawia, że stają się one obserwacją, a nie uniwersalną prawdą.
Code review to nie tylko wyłapywanie błędów. Równie ważne jest docenianie tego, co zostało zrobione dobrze. Dlatego nie ograniczaj się do krytyki. Zwracaj też uwagę na dobre praktyki, sprytne rozwiązania czy solidnie napisane testy. Takie podejście działa podwójnie: z jednej strony wzmacnia pozytywne zachowania, a z drugiej sprawia, że autor jest bardziej otwarty na Twoje uwagi. No i zwyczajnie - morale w zespole rośnie. Dzięki temu review staje się wspólnym procesem uczenia się i poprawiania jakości, a nie przykrym obowiązkiem czy festiwalem hejtu.
Dwie praktyczne wskazówki:
Na koniec dwie małe rady w kwestiach praktycznych:
Jeśli trzeba, komentuj po linijce. Tak łatwiej wskazać, gdzie dokładnie leży problem. Zamiast pisać ogólny komentarz do całego pull requesta, który brzmi: zmień nazewnictwo zmiennych..., możesz wskazać konkretną linię kodu, gdzie nazwa jest niejasna. To eliminuje zgadywanie ze strony autora. Dobrze ukierunkowane komentarze są o wiele skuteczniejsze i mniej frustrujące niż długie, ogólne uwagi.
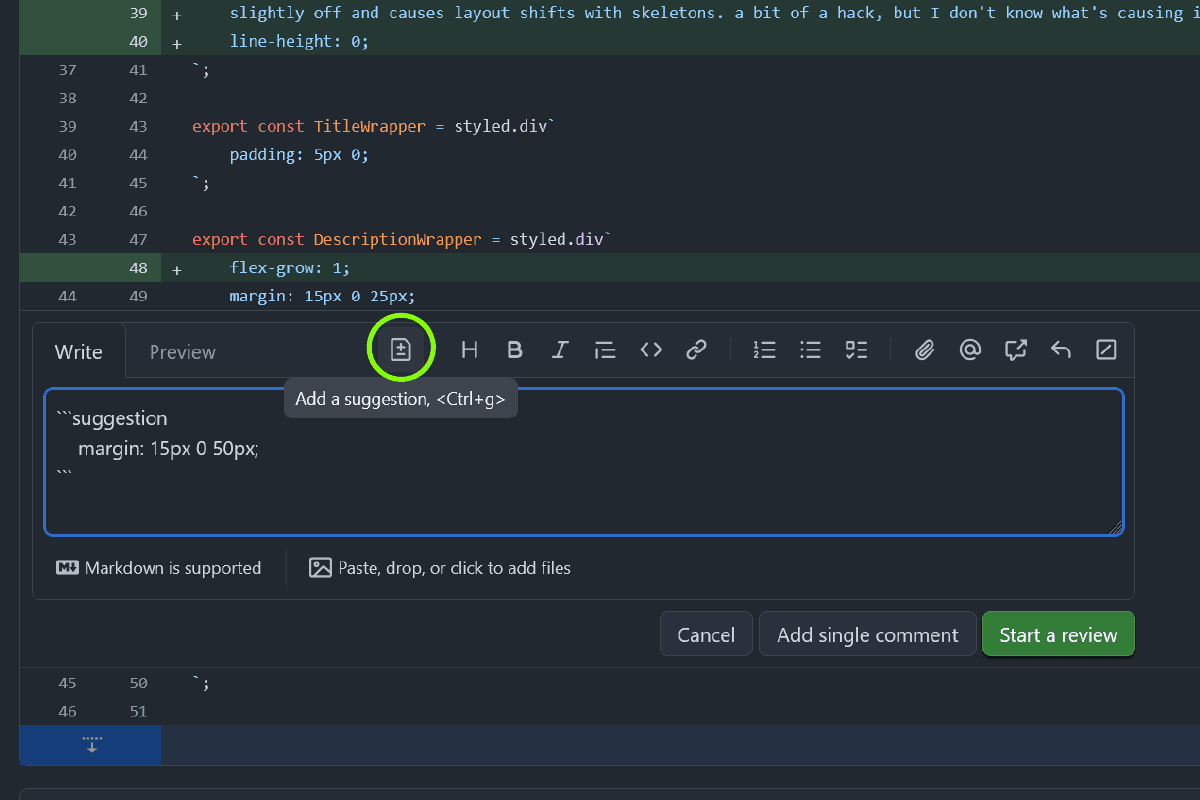
Używaj suggestion mode w GitHub. To pozwala autorowi zaakceptować poprawki jednym kliknięciem. Tryb sugestii to funkcja w popularnych narzędziach do code review, która pozwala recenzującemu zaproponować konkretną zmianę w kodzie. Autor PR-a może ją zaakceptować jednym kliknięciem, co automatycznie tworzy commit z poprawką. Jak to wygląda w praktyce? W GitHubie, podczas dodawania komentarza do linii kodu, możesz użyć specjalnej składni, aby zamienić go w sugestię.
Podsumowanie
Code review to dialog: recenzujący przekazuje informację zwrotną, autor nanosi poprawki, a całość jest ponownie sprawdzana. Proces trwa do momentu, aż obie strony uznają efekt za satysfakcjonujący. To także realne wsparcie w rozwoju. Możesz zobaczyć, jak pracują inni, porównać praktyki i uczyć się z ich doświadczeń. Dodatkowo każdy fragment aplikacji jest znany przynajmniej dwóm osobom, co sprzyja dzieleniu się wiedzą i zapobiega sytuacji, w której ktoś zna wyłącznie część systemu, nad którą sam pracuje.
Nadrzędnym celem jest to, by każdy PR opuszczał code review z wyższą jakością, niż do niego wszedł, a nie osiągnięcie doskonałości w jednym kroku. Przyłożenie się do code review to inwestycja - wymaga czasu i świadomego wysiłku. Ale uwierz, zwrot w postaci mniejszej liczby błędów produkcyjnych i lepiej utrzymywalnego kodu, jest nie do przecenienia.




