

Kod jest czytany znacznie częściej, niż jest pisany. Ta prosta obserwacja ma dość głębokie implikacje. W praktyce oznacza, że optymalizacja pod kątem czytelności i zrozumiałości może okazać się jedną z najważniejszych i najbardziej opłacalnych inwestycji w jakość, stabilność i długoterminowe koszty utrzymania projektu. Nazwy stanowią circa 70% kodu. Ciężko więc jakkolwiek zaprzeczyć, że są istotne.
Style nazewnictwa
Różnorodność stylów nazewnictwa wynika z historii języków programowania i ograniczeń technicznych. Niezależnie od tego, który styl wybierzemy, konieczne jest spójne trzymanie się tego „pomysłu” w całym projekcie. Bez tego nieuchronnie pogrąży się on w chaosie! Ciekawostką jest potwierdzony badaniami fakt, że szansa, by dwie osoby niezależnie od siebie użyły tej samej nazwy w odniesieniu do tego samego obiektu, wynosi jedynie 7 - 18% (The vocabulary problem in human-system communication). Tak niski poziom zgodności pokazuje, jak ważne są formalne konwencje nazewnicze.
Jakie są podstawowe konwencje nazewnicze
snake_case: styl ten, używający podkreślnika do oddzielania słów, ma swoje korzenie w latach 60. i jest silnie związany z językiem C oraz środowiskiem Unix. W tamtych czasach podkreślnik był najbardziej dostępnym znakiem do separacji słów w identyfikatorach. Znaki typu spacja, myślnik czy kropka miały w kodzie inne znaczenie i funkcje. Podkreślnik nie kolidował z operatorami i łatwo było nim imitować spację. A dodatkowo był obecny na maszynopisarskich i komputerowych klawiaturach od samego początku. Inne znaki, które mogłyby służyć jako separator, często nie były jeszcze powszechne albo nie nadawały się semantycznie.
camelCase i PascalCase: style, które używają wielkich liter do oddzielania słów, zyskały na popularności wraz z językami takimi jak Pascal, a później Java i C#. W tych językach myślnik był zarezerwowany jako operator odejmowania, co uniemożliwiało jego użycie w identyfikatorach. Przyjęło się, że PascalCase (gdzie każde słowo zaczyna się wielką literą) jest używany do nazywania typów, klas i interfejsów, natomiast camelCase (gdzie pierwsze słowo zaczyna się małą literą) jest stosowany dla zmiennych, metod i funkcji. Choć tak naprawdę, w praktyce bywa różnie 😊 i raczej nie należy przywiązywać się do tego podziału.
kebab-case: styl z myślnikiem jako separatorem jest historycznie związany z językiem LISP. Dziś jego użycie w identyfikatorach kodu jest rzadkie, ale stał się standardem w świecie web developmentu, gdzie jest powszechnie stosowany w nazwach plików CSS oraz w adresach URL dla poprawy czytelności.
Jak tworzyć samodokumentujący się kod
Idea "kodu samodoskumentującego się" stanowi efekt dążenia do maksymalnej czytelności. Jest to paradygmat, w którym kod jest napisany w taki sposób, że jego struktura, a przede wszystkim nazewnictwo, jasno i jednoznacznie komunikują jego przeznaczenie i działanie, minimalizując potrzebę dodatkowych komentarzy. Zgodnie z tą ideą, kod ma "mówić sam za siebie", dlatego komentarze nie powinny tłumaczyć jego działania . Zamiast tego, powinny one wyjaśniać, dlaczego coś jest robione w określony sposób, na przykład uzasadniając wybór algorytmu czy odwołując się do specyficznych wymagań biznesowych.
Osiągnięcie samodoskumentującego się kodu opiera się na kilku technikach, które bezpośrednio wiążą się z nazewnictwem:
Używaj opisowych nazw zmiennych
To najprostsza, a zarazem najważniejsza technika. Każda nazwa staje się mini-dokumentacją, a struktura kodu odzwierciedla logiczny podział problemu na mniejsze, zrozumiałe części. Unikamy nic niemówiących nazw dla zmiennych i zastępujemy je takimi, które wnoszą nowe informacje do naszego systemu.
A co ze zmiennymi w pętlach?
Powszechna praktyka pokazuje, że wewnątrz pętli bardzo często wykorzystywane są krótkie, jednoliterowe nazwy zmiennych (i, j, k...). A przecież przed chwilą wskazaliśmy, że to nie najlepszy pomysł. Rozwiązaniem tej pozornej sprzeczności jest zasięg. Zmienna i w pętli for istnieje tylko przez kilka linijek kodu. Jej kontekst i cel są w 100% zdefiniowane przez strukturę pętli, widoczną w całości na jednym ekranie. Nie ma potrzeby, aby jej nazwa niosła dodatkowe informacje, ponieważ cały jej "świat" jest natychmiastowo dostępny. Z drugiej strony, zmienna globalna czy pole w klasie mają szeroki zasięg i długi czas życia. Miejsce ich wykorzystania jest często oddalone od miejsca definicji. W tym przypadku to nazwa musi nieść ze sobą cały niezbędny kontekst. Czasem nazywane jest to regułą zasięgu.
Zastępuj "magiczne" wartości stałymi
Zamiast używać w kodzie surowych liczb albo ciągów znaków, które nie mają oczywistego znaczenia (tzw. "magic numbers" i "magic strings"), należy je zastąpić stałymi o opisowych nazwach.
Programista czytający Pierwotny kod musi domyślać się, że 15000 to 15 sekund. W drugim przypadku intencje są jasne. REQUEST_TIMEOUT_MS od razu informuje, że chodzi o milisekundy.
Wyodrębniaj złożone warunki i obliczenia
Złożone warunki logiczne lub skomplikowane obliczenia powinny być wyodrębniane do osobnych funkcji, których nazwa precyzyjnie opisuje, co robią.
Jakie są zasady nazewnictwa w kodzie
Zasady, które za chwilę przedstawię tworzą coś więcej niż tylko listę zaleceń. Układają się w spójny system gramatyczny dla kodu. W tej gramatyce klasy (rzeczowniki) pełnią rolę podmiotów, metody (czasowniki) są orzeczeniami, a zmienne (inne rzeczowniki) dopełnieniami. Kod napisany zgodnie z tymi zasadami zaczyna przypominać proste, deklaratywne zdania, co drastycznie obniża barierę poznawczą potrzebną do jego zrozumienia. Na przykład, wyrażenie summary.exportAsPDF("daily_brief") czyta się niemal jak zdanie: "Export summary as PDF named daily_brief". Chodzi o jak najlepsze przekształcenie kodu z serii instrukcji dla maszyny w serię zrozumiałych dla człowieka stwierdzeń.

Zmienne logiczne jako pytania
Nadawanie zmiennym typu boolean nazw, które zaczynają się od prefiksów takich jak is, has czy can, przekształca je w pytania o stan, na które odpowiedzią jest prawda lub fałsz. Główną zaletą tej konwencji jest to, że kod warunkowy, który z nich korzysta, czyta się jak język naturalny. Dobrą praktyką jest też stosowanie nazw "pozytywnych". Zmienna isEnabled brzmi lepiej niż isDisabled. Głównym powodem jest eliminacja podwójnych zaprzeczeń, które są trudniejsze do przetworzenia przez ludzki mózg.
Warunek if (user.admin) sprawia, że programista musi się na chwilę zatrzymać i zadać kilka pytań, ponieważ nie jest jasne, czym user.admin właściwie jest:
Czy to wartość logiczna (boolean)? Czy
user.adminprzechowujetruelubfalse? To najbardziej prawdopodobny scenariusz, ale nie jedyny.Czy to obiekt z dodatkowymi danymi? Może
user.adminto obiekt, który istnieje tylko dla adminów, a dla zwykłych użytkowników ma wartośćnullalboundefined?Czy to rola w formie tekstu (string)? Może
user.adminto pole, które przechowuje nazwę roli, np."editor", a dla zwykłego użytkownika jest pustym stringiem""?
Główny problem polega na tym, że nazwa admin opisuje rzecz (rzeczownik), a nie stan. To zmusza programistę do analizowania struktury obiektu user, aby zrozumieć, jak ten warunek naprawdę działa.
Nazwa user.isAdmin rozwiązuje wszystkie powyższe problemy, ponieważ jest pytaniem, na które odpowiedź może brzmieć tylko "tak" (true) lub "nie" (false). Prefiks is (podobnie jak has, can, should) jest powszechnie przyjętą konwencją w programowaniu do nazywania właściwości lub funkcji, które zwracają wartość logiczną.
W takim przypadku programista natychmiast wie, że:
Sprawdza stan, a nie pobiera złożonych danych.
Oczekuje, że
isAdminbędzie miało wartośćtruelubfalse.Kod czyta się niemal jak naturalne zdanie w języku angielskim: "If user is admin...".
Wszystko to eliminuje potrzebę zgadywania i zaglądania do definicji obiektu. Kod staje się samoopisujący.
Metody i funkcje jako czasowniki
Funkcje i metody są jednostkami wykonawczymi w kodzie: przeprowadzają operacje lub zmieniają stan. Wykorzystanie czasowników do nazywania ich jest najbardziej naturalnym i precyzyjnym sposobem opisania ich działania. Np. nazwa taka jak sendConfirmationEmail(user) nie pozostawia wątpliwości, co się stanie po wywolaniu tej funkcji. Chodzi o sytuację, gdy zmiennej nadaje się nazwę, która sugeruje coś innego niż faktycznie przechowuje.
Dodatkowo, zasada ta ma też wartość diagnostyczną. Jeśli masz trudności z nazwaniem funkcji za pomocą jednego, zwięzłego czasownika, to sygnał, że robi ona zbyt wiele rzeczy naraz i łamie Single Responsibility Principle. Np. funkcja o nazwie processOrderAndSendConfirmation(orderData, customerData), prawdopodobnie powinna zostać rozbita na mniejsze, bardziej wyspecjalizowane frakcje, takie jak np. validateOrderData(), updateInventory(items) i sendConfirmation().
Dla przykładu, kod function price(items) nie informuje, czy pobiera ona cenę, ustawia ją, czy oblicza. Za to function calculateTotalPrice(items) precyzyjnie opisuje wykonywaną operację.
Klasy i obiekty jako rzeczowniki
W programowaniu obiektowym klasy i obiekty stanowią modele bytów i koncepcji. Dlatego ich nazwy powinny być rzeczownikami, które odzwierciedlają to, czym są, a nie co robią. Nazwy takie jak User, ShoppingCart, Invoice czy DatabaseConnection będą jasne i intuicyjne. class ManageUsers sugeruje akcję, nie byt. Za to class UserRepository lub class UserManagementService precyzyjnie opisują odpowiedzialność klasy jako repozytorium lub serwisu.
Warto też unikać generycznych nazw zakończonych na -Manager, -Processor czy -Info. Są one często słowami-wytrychami, które nic nie mówią o prawdziwej odpowiedzialności klasy i mogą maskować wady projektowe. Klasa o nazwie UserManager często jest tzw. God Object, który agreguje zbyt wiele, często niepowiązanych ze sobą, odpowiedzialności. Lepszym podejściem jest nazwanie klas zgodnie z ich specyficzną rolą, np. UserRepository (do operacji na danych), UserValidator (do walidacji) czy UserFactory (do tworzenia obiektów).
Kolekcje w liczbie mnogiej
Ta prosta konwencja ma zaskakująco duży wpływ na czytelność i unikanie błędów. Użycie liczby mnogiej dla zmiennych przechowujących kolekcje (tablice, listy, zbiory) natychmiast informuje nas o naturze danych, bez konieczności sprawdzania ich typu czy miejsca definicji. Nazwa user silnie sugeruje pojedynczy obiekt, podczas gdy users jednoznacznie wskazuje na kolekcję wielu takich obiektów.
Pomaga to unikać prostych, ale częstych błędów, takich jak próba odwołania się do właściwości na kolekcji (users.name) zamiast na jej elemencie (user.name wewnątrz pętli) lub próba iteracji po pojedynczym obiekcie (user.forEach(...)). Kod for (const user of users) czyta się naturalnie i jest semantycznie poprawny.
Prefiksy dla handlerów zdarzeń (on lub handle)
Spójne nazywanie funkcji obsługujących zdarzenia jest istotne dla utrzymania porządku. Używanie standardowych prefiksów, takich jak on i handle, tworzy przewidywalny i łatwy do zrozumienia wzorzec.
Konwencja często jest następująca: prefiks on (np. onClick, onSubmit) jest używany w nazwie właściwości lub atrybutu, do którego przypisuje się funkcję obsługującą. Sama funkcja (handler) często otrzymuje prefiks handle (np. handleClick, handleSubmit). Na przykład, w komponencie React możemy zobaczyć <button onClick={this.handleClick}>. Ta spójność sprawia, że już na pierwszy rzut oka widać, które funkcje są bezpośrednio powiązane z interakcjami użytkownika lub zdarzeniami systemowymi.
Antywzorce nazewnicze - czego unikać
Chodzi tu o praktyki, które na pierwszy rzut oka mogą wydawać się logiczne albo wygodne, ale w dłuższej perspektywie generują komplikacje. Często bywają także symptomem głębszych problemów z projektem i architekturą systemu. Nazwa taka jak UserManager nie jest zła tylko dlatego, że jest nieprecyzyjna. Ale dlatego, że sygnalizuje istnienie wspomnianego wcześniej God Object, który łamie Single Responsibility Principle, biorąc na siebie zbyt wiele zadań. Trudność w znalezieniu dobrej, zwięzłej nazwy dla klasy lub funkcji jest często sygnałem, że dany element został źle zaprojektowany. Dlatego walka z antywzorcami nazewniczymi staje się narzędziem diagnostycznym. Bo zmiana nazwy często pociąga za sobą konieczność modyfikacji struktury kodu, prowadząc do czystszej i bardziej modułowej architektury.
Notacja węgierska
Notacja węgierska to przykład konwencji, która narodziła się z potrzeby rozwiązania realnego problemu, ale z czasem jej zniekształcona forma stała się jednym z najbardziej rozpoznawalnych antywzorców w programowaniu.
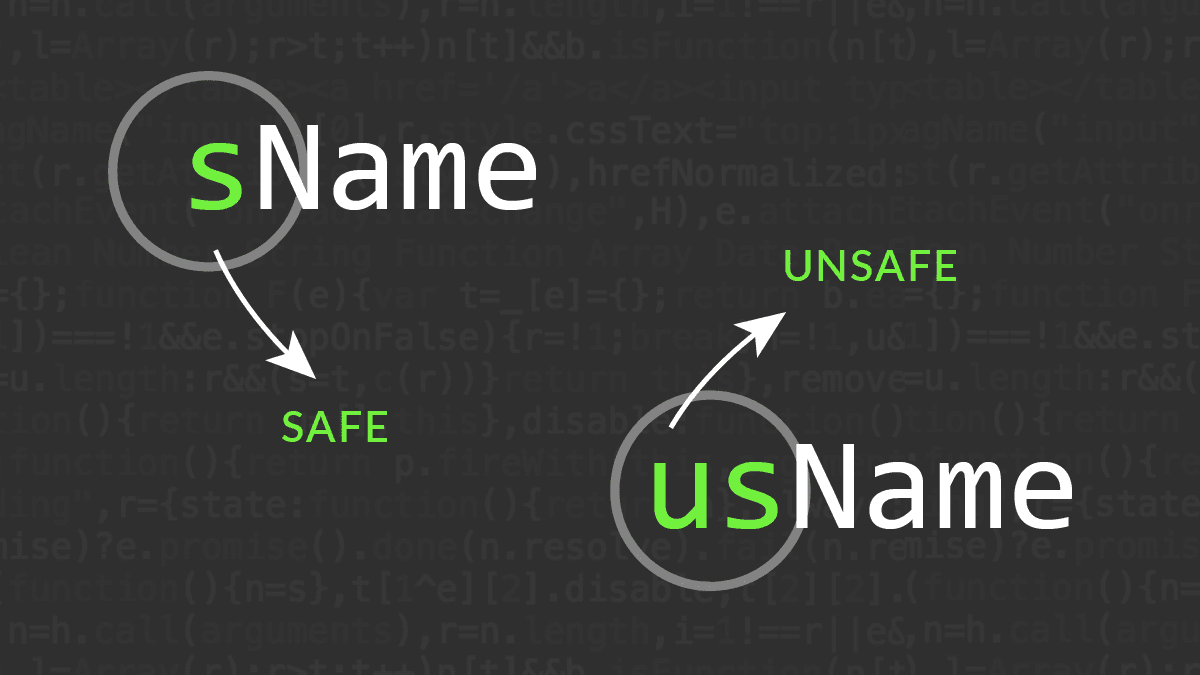
Apps Hungarian (oryginalna forma):
Wprowadzona przez Charlesa Simonyi'ego w Microsofcie, polegała na dodawaniu prefiksu opisującego semantyczne znaczenie lub "rodzaj" zmiennej, a nie jej typ danych. Przykładem może być usName dla "unsafe string" (ciąg znaków niepoddany walidacji) i sName dla "safe string" (ciąg znaków bezpieczny do użycia). Ta forma miała na celu zapobieganie błędom logicznym, np. użyciu niebezpiecznych danych w wrażliwym kontekście.
Systems Hungarian (zdegradowana, późniejsza forma):
Jast to uproszczona i zniekształcona forma Apps Hungarian, w której prefiksy opisują fizyczny typ danych. Przykłady to strName dla stringa, iCounter dla integera, bIsEnabled dla booleana. Warto też wspomnieć, że historycznie w wielu językach (np. C#, Delphi, ActionScript) przyjęło się poprzedzać literą I interfejsy, i robi się tak do dzisiaj. TS natomiast zwalcza tę praktykę. Ale wróćmy do Systems Hungarian. To właśnie tę formę powszechnie uznaje się za antywzorzec. A jest tak z kilku powodów:
Redundancja - współczesne, silnie typowane języki programowania oraz zintegrowane środowiska programistyczne (IDE) znają typ każdej zmiennej. Umieszczanie tej informacji w nazwie jest zbędnym powtórzeniem, które zaśmieca kod i nie dodaje żadnej nowej wartości.
Możliwość dezaktualizacji - największą wadą tej notacji jest to, że staje się źródłem dezinformacji podczas refaktoryzacji. Jeśli programista zmieni typ zmiennej z
intnalong, ale zapomni zaktualizować jej nazwę, nagle staje się ona "fałszywa". I jest to znacznie gorsze niż zupełny brak informacji o typie. Z tego samego powodu także komentarze opisujące działanie kodu nie są najlepszym pomysłem, bo wymagają dodatkowego utrzymywania i mogą się dezaktualizować.Utrudniona czytelność - prefiksy typów sprawiają, że nazwy stają się dłuższe, trudniejsze do wymówienia i mniej czytelne. Zamiast skupiać się na biznesowym znaczeniu zmiennej, programista musi najpierw przetworzyć informację o jej typie.
Inne pułapki nazewnicze
Oprócz notacji węgierskiej, istnieje wiele innych powszechnych pułapek nazewniczych, na które warto mieć baczenie ;) A mianowicie:
Mylące nazwy
Chodzi o sytuację, gdy zmiennej nadaje się nazwę, sugerującą coś innego niż faktycznie ona przechowuje. Typowym przykładem jest nazwanie kolekcji accountList, podczas gdy w rzeczywistości jest to Set, Dictionary lub inny typ danych, który nie jest listą. Taka nazwa wprowadza w błąd co do właściwości i dostępnych operacji na danej strukturze.
Niejasne rozróżnienia
Pojawiają się, gdy w kodzie używamy wielu synonimów do opisania tej samej koncepcji bez jasnego zdefiniowania różnic między nimi. Jeśli w jednym miejscu dane są pobierane przez funkcję fetchUsers(), w innym przez getUsers(), a w jeszcze innym przez retrieveUsers(), programista czytający kod musi się zastanawiać, czy istnieje między nimi jakaś subtelna różnica. Jeśli nie, to takie nazewnictwo wprowadza niepotrzebny szum informacyjny i zamieszanie. Należy wybrać jedno słowo na jedną koncepcję i trzymać się go konsekwentnie w całym projekcie.
Słowa-wytrychy
Są to generyczne, nic nieznaczące słowa, które często dodaje się do nazw klas lub zmiennych, takie jak Data, Info, Manager, Processor, Object czy Util. Nazwa klasy ProductData nie wnosi żadnej dodatkowej informacji w porównaniu do Product. Nazwa TaskManager jest niejasna, bo co dokładnie oznacza "Manager"? Takie nazwy często maskują słaby projekt i brak jasno zdefiniowanej odpowiedzialności.
Zbyt krótkie lub zbyt długie nazwy
Nazwy powinny być adekwatne do swojego kontekstu. Nieprawidłowe będzie zarówno używanie kryptonimicznych, jednoliterowych nazw dla zmiennych o szerokim zasięgu (np. globalna zmienna c oznaczająca customer), jak i tworzenie przesadnie długich, rozwlekłych nazw dla zmiennych o bardzo wąskim zakresie. Celem jest znalezienie złotego środka, gdzie nazwa jest tak długa, jak to konieczne, i tak krótka, jak to możliwe, bez utraty kluczowych informacji.
Skróty i „magiczne nazwy”
są z natury niejednoznaczne i zależne od kontekstu. Skrót usr może oznaczać user, ale w innym systemie universal_serial_port. Skrót pc_reader może być interpretowany jako price_count_reader lub personal_computer_reader. Każda taka niejednoznaczność zmusza programistę do dodatkowego wysiłku w celu odgadnięcia intencji autora, zwiększając ryzyko pomyłki. W erze nowoczesnych, zintegrowanych środowisk programistycznych (IDE) z zaawansowanym autouzupełnianiem kodu, argument oszczędności czasu na pisaniu jest całkowicie nieaktualny. Czas zaoszczędzony na wpisaniu kilku znaków jest wielokrotnie tracony za każdym razem, gdy ktoś (w tym sam autor po kilku miesiącach) musi rozszyfrować znaczenie skrótu.
Spójne i przemyślane nazewnictwo tworzy wspólny język, który minimalizuje nieporozumienia i umożliwia recenzje kodu skupiające się na architekturze i logice biznesowej, a nie na żmudnym rozszyfrowywaniu, co autor miał na myśli.




