

setTimeout i setInterval to jedne z pierwszych metod, których uczy się każdy nowy programista lub programistka JavaScript. Problem polega na tym, że zdecydowana większość kursów, wspomina jedynie o ich zaletach, nie mówiąc ani słowa o potencjalnych zagrożeniach, wynikających z nieświadomego użycia. Właśnie dlatego, to na nich skupimy się w artykule. Będzie też trochę o pętli zdarzeń, przeglądarkach internetowych i alternatywnych rozwiązaniach.
Jeżeli wcześniej nie zetknąłeś/aś się z tymi metoda, to zachęcam Cię do przeczytania całości, ponieważ w pierwszej części wyjaśniam ich działanie i podstawowe wykorzystanie.
setTimeout i setInterval
Zacznijmy od tego, że ani setTimeout, ani setInterval, nie są częścią oficjalnej specyfikacji języka ECMAScript (a tym samym JavaScript) - obie metody są nam dostarczane przez przeglądarki. Okazuje się jednak, że dla zachowania spójności, zostały zaimplementowane również przez twórców środowisk serwerowych, na przykład w Node lub Bun. Warto mieć jednak na uwadze, że wykorzystując JavaScript w IoT możemy nie mieć ich do dyspozycji.
Obie metody służą do wykonywania kodu z opóźnieniem, obie są asynchroniczne i obie mają takie same parametry. Tu jednak podobieństwa się kończą.
Zacznijmy od prostego przykładu. Wykorzystamy setTimeout do wykonania funkcji po upływie co najmniej 3 sekund. Musimy zatem przekazać dwa argumenty: funkcję, którą chcemy wykonać oraz czas wyrażony w milisekundach, po upływie którego, dana funkcja powinna zostać wywołana. W kodzie wygląda to następująco:
W przykładzie wyżej, kod zostanie wykonany tylko raz. Jeżeli jednak zastosujemy zamiast setTimeout, setInterval, to będzie on wykonywać przekazaną funkcję, dopóki nie zostanie zatrzymany. Działa on podobnie do pętli nieskończonej z wbudowanym mechanizmem opóźnienia.
Możliwości tych dwóch metod nie kończą się jednak na dwóch argumentach. Zarówno do jednej, jak i do drugiej, możemy przekazać dowolną ich liczbę. Zostaną one przekazane do funkcji, która jest pierwszym argumentem. Dzięki temu nie musimy "opakowywać" jej w dodatkową funkcję by uniknąć natychmiastowego wywołania.
setTimeout oraz setInterval posiadają swoje odpowiedniki służące do przerwania oczekującego wywołania. Są to odpowiednio: clearTimeout i clearInterval. Żeby z nich skorzystać, musimy jednak znać id danego interwału lub opóźnienia. To jednak żaden problem, ponieważ setTimeout oraz setInterval zwracają swój id w momencie wywołania.
Mamy zatem dwie metody: jedna z nich służy do jednorazowego wywołania funkcji z opóźnieniem, a druga wywołuje przekazaną funkcję co określony czas. W praktyce jednak obie metody mają swoje wady, a ich asynchroniczna natura potrafi skutecznie maskować potencjalne problemy. Zrozumienie ograniczeń i specyfiki działania, pozwala uniknąć problemów w przyszłości.
Event loop i inne problemy
JavaScript jest językiem jednowątkowym. Jeżeli działamy w środowisku przeglądarkowym to mamy do dyspozycji również workery, które dają nam namiastkę wielowątkowości. Nie zmienia to jednak faktu, że działanie wszystkich funkcji asynchronicznych (w tym także setTimeout i setInterval) jest nieodłącznie związane z pętlą zdarzeń, która ma kluczowy wpływ na ich zachowanie.
We wcześniejszym przykładzie wspomniałem, że funkcja wykona się za co najmniej 3000 milisekund. Nie oznacza to jednak, że wykona się dokładnie po tym czasie. Możemy mieć jedynie pewność, że nie wykona się ona wcześniej. Wpływ na to kiedy zostanie wywołana ma oczywiście wspomniana przed chwilą pętla zdarzeń.
W środowisku przeglądarkowym obsługą setTimeout oraz setInterval zajmuje się WebAPI i to właśnie ten mechanizm powiadamia silnik JavaScriptu, że nadszedł czas na wykonanie funkcji. Może się jednak okazać, że w momencie, w którym powinna zostać wykonana funkcja asynchroniczna, silnik zajęty jest wykonywaniem innego kodu. W takim przypadku asynchroniczna funkcja oczekuje na swoją kolej w jeden z dwóch kolejek: mikro zadań lub (makro) zadań. W przypadku setTimeout i setInterval jest to ta druga. Następnie trafia ona na stos wywołań (ang. call stack). To jednak może nastąpić dopiero w momencie, w którym jest on pusty. Szczegółowe wyjaśnienie pętli zdarzeń znajdziesz w tym artykule.
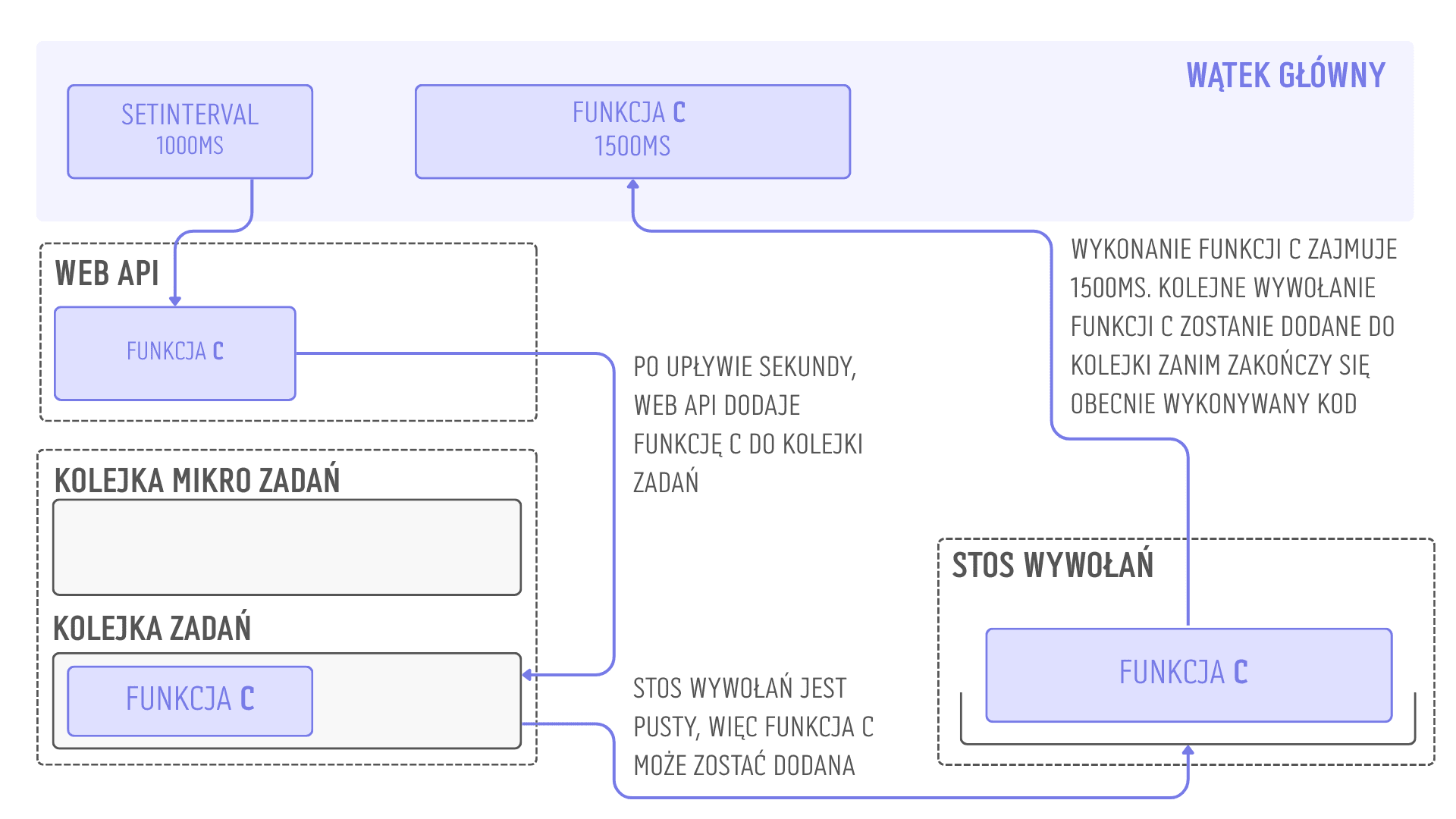
Dokładnie ten sam mechanizm ma miejsce także w przypadku zastosowania setInterval. Tu jednak pojawia się jeszcze jeden problem. Działanie setInterval przypomina pętlę, a więc będzie dodawać do kolejki zadań kolejne wywołania funkcji, dopóki nie zostanie zakończony. Jeżeli wykonanie takiej funkcji zajmuje więcej czasu, niż wynosi opóźnienie w setInterval, to dojdzie do kolejkowania kolejnych wywołań i wykonywania ich natychmiast po zakończeniu działania poprzedniej funkcji (zakładając, że żaden inny kod nie będzie miał wyższego priorytetu). W efekcie nie uzyskamy oczekiwanego opóźnienia pomiędzy kolejnymi wywołaniami.
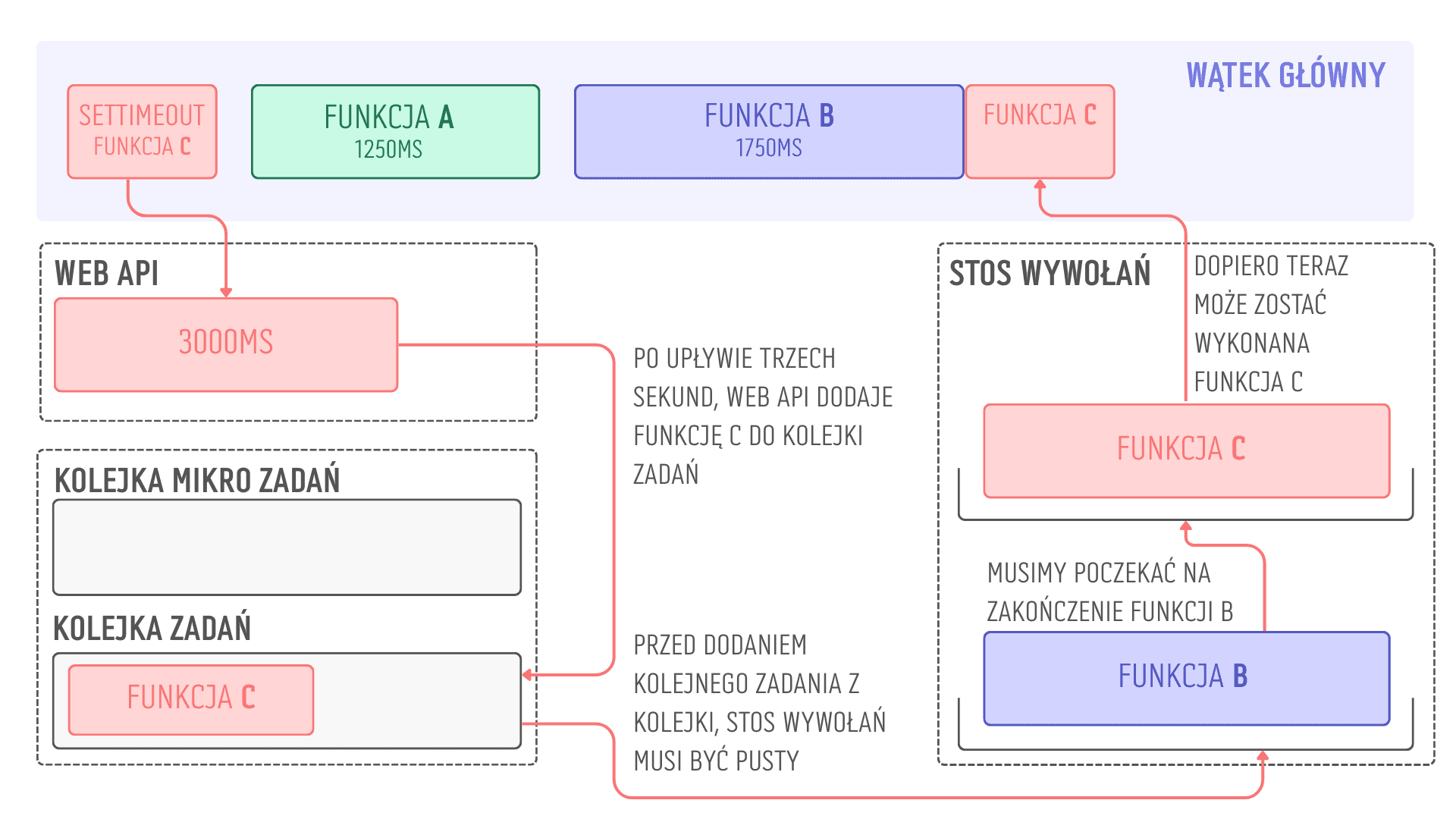
Przepływ danych przedstawiony na grafice powyżej można opisać następująco:
Interpreter natrafia na linię kodu w której znajduje się
setTimeout. Wykonuje ją, a dalszą obsługą zajmuje się Web APIPo upływie 3000ms Web API powiadamia silnik JavaScriptu, że funkcja C powinna zostać wykonana
Funkcja C jest asynchroniczna. W związku z tym zostaje dodana do kolejki zadań
W kolejnej iteracji pętla zdarzeń sprawdza obie kolejki i natrafia na zadanie do wykonania w jednej z nich. Nie może jednak dodać go natychmiast do stosu wywołań, bo nie jest on pusty - aktualnie znajduje się tam funkcja B, której wykonanie rozpoczęło się wcześniej i trwa 1750 milisekund
Po zakończeniu funkcji B i usunięciu jej ze stosu, możemy w końcu wykonać funkcję C
Łączny czas oczekiwania wyniósł ponad 3 sekundy. Stało się tak dlatego, że w trakcie oczekiwania na
setTimeout, silnik nadal wykonuje inne instrukcje. Funkcja C musi zaczekać do momentu aż stos wywołań będzie pusty.
Takie zachowanie setInterval występuje zawsze, a przypadek przedstawiony powyżej jest jego skrajnym przykładem. Warto jednak mieć na uwadze, że w przypadku setInterval, odstępy liczone są od momentu dodania funkcji do kolejki zadań, a nie od momentu zakończenia jej działania. Oznacza to, że podajemy odstęp pomiędzy kolejnymi wywołaniami i zupełnie nie bierzemy pod uwagę czasu potrzebnego na wykonanie kodu. Wykorzystując setInterval warto zadbać o odpowiednio duże opóźnienie, żeby uniknąć kolejkowania.
Na tym jednak nie koniec problemów. Musimy pamiętać o kolejności wykonywania zadań - mikro zadania mają priorytet. Zakończony Promise zostanie wykonany wcześniej, co dodatkowo może opóźnić wykonywanie makro zadań.
Jakby tego było mało, wszystkie liczące się na rynku przeglądarki, stosują wiele mechanizmów, które mają na celu ograniczenia zużycia zasobów (RAM, CPU, bateria itd.). W efekcie, wszystkie otwarte karty, które nie są obecnie aktywne zostają znacznie ograniczone, a jednym ze skutków jest znacznie rzadsze wykonywanie funkcji w setInterval - zazwyczaj jest to raz, na około 1000 ms (w nowszych wersjach Chrome’a, ten czas potrafi dochodzić nawet do minuty). Jeżeli interwał ustawiony został np. na 300 ms, to po przełączeniu przez użytkownika karty, zostanie spowolniony do jednej sekundy.
Nawet w aktywnej karcie istnieją ograniczenia. Zazwyczaj przeglądarki nie pozwalają na odstęp mniejszy niż 4 ms pomiędzy kolejnymi wywołaniami w setInterval. Oczywiście nic nie stoi na przeszkodzie, żeby podać cyfrę mniejszą niż 4, ale w praktyce, odstęp ten i tak zostanie przez przeglądarkę zwiększony i stanie się to bez poinformowania programisty o tym fakcie. Różnica nie jest znacząca i w zdecydowanej większości przypadku nie będzie miała żadnego wpływu na działanie programu. Jest to jednak kolejny punkt, o którym warto wiedzieć.
Niestety w prawdziwym świecie nie da się przewidzieć i zaplanować dokładnego działania programu. Interakcje użytkownika mają wpływ na wykonywany obecnie kod, a wykorzystanie frameworków i bibliotek dodatkowo utrudnia zrozumienie aplikacji. Pozostaje nam jedynie zaakceptować powyższe ograniczenia i mieć je w głowie w trakcie pisania kodu.
Alternatywy
Środowisko przeglądarkowe daje nim kilka innych opcji, które możemy wykorzystać jako alternatywę dla setTimeout lub setInterval. Nie oznacza to, że są one lepsze. Działają inaczej, a wybór rozwiązanie zależy jak zwykle od problemu z którym się mierzymy. Nie ma też rozwiązania idealnego - każde z nich ma swoje wady i zalety.
Rekurencyjny setTimeout
Rekurencyjny setTimeout daje programiście znacznie większą kontrolę nad kolejnymi wywołaniami. Zamiast przechowywać id interwału w celu późniejszego zatrzymania, możemy po prostu zastosować instrukcję warunkową. W zdecydowanej większości przypadków taki kod jest czytelniejszy i łatwiejszy w utrzymaniu.
Dodatkowo mamy gwarancję, że kolejne wywołania nie nałożą się na siebie, a odstęp czasowy między nimi zawsze wyniesie minimum tyle, ile wskazaliśmy.
RequestAnimationFrame
requestAnimationFrame to metoda udostępniana przez obiekt window. Oznacza to, że możemy z niej skorzystać wyłącznie w środowisku przeglądarkowym (frontend).
Nie jest ona jednak tak uniwersalna, jak setTimeout i setInterval ponieważ odstęp pomiędzy kolejnymi wywołaniami zależeć będzie od wyświetlacza użytkownika. Im szybciej jest on odświeżany, tym częściej wywoływana będzie przekazana do środka funkcja.
Jest to zatem idealne rozwiązanie do tworzenia płynnych animacji lub gier przeglądarkowych. Dodatkowo requestAnimationFrame jest automatycznie zatrzymywany w momencie, gdy karta przeglądarki nie jest aktywna.
WebWorkers
Workery to kolejna z możliwości. Dzięki nim możemy wykonywać kod, bez blokowania głównego wątku aplikacji. Nie są co prawda bezpośrednią alternatywą dla setTimeout ani setInterval, ale mogą okazać się niezwykle przydatne w połączeniu z nimi - setInterval uruchomiony w osobnym wątku nie będzie "walczyć" o miejsce z pozostałą częścią kodu. W efekcie aplikacja może być bardziej responsywna z perspektywy użytkownika.
O web workerach można by mówić znacznie dłużej, dlatego zdecydowałem się poświęcić im osobny artykuł. Znajdziesz go tutaj.
Co wybrać?
Wybór odpowiedniego rozwiązania zależy jak zwykle od problemu, który próbujemy rozwiązać. Mimo, że setInterval charakteryzuje się niższą precyzją i trudniejszym do przewidzenia momentem wywołania, niż jego rekurencyjny odpowiednik z użyciem setTimeout, to nadal ma on swoje zastosowanie zarówno we frontendzie, jak i backendzie.
W tabeli poniżej porównałem setInterval oraz rekurencyjny setTimeout:
setInterval | Rekurencyjny setTimeout | |
|---|---|---|
Sposób wywoływania | Stały odstęp czasowy. Planuje wykonanie na podstawie czasu rozpoczęcia, niezależnie od czasu trwania zadania. | Samonapędzająca się pętla. Planuje kolejne zadanie dopiero po zakończeniu obecnego. |
Zachowanie przy długim zadaniu synchronicznym | Kolejkuje następne wywołania. Może prowadzić do wykonywania zadań jedno po drugim bez przerw, blokując UI. | Czeka na zakończenie zadania. Następnie planuje kolejne wywołanie po określonym opóźnieniu. |
Zachowanie przy zadaniu asynchronicznym | Wysyła nowe żądania w stałych odstępach, co może prowadzić do nawarstwiania się żądań i przeciążenia serwera. | Planuje kolejne żądanie dopiero po tym, jak poprzednie zostanie rozwiązane lub odrzucone. |
Kontrola interwału | Aby zmienić opóźnienie, wymaga użycia clearInterval i ponownego utworzenia instancji. | Opóźnienie może być dynamicznie obliczane przed każdym nowym wywołaniem |
Obsługa błędów | Nie zatrzymuje się przy błędzie. Kontynuuje wielokrotne wywoływanie wadliwego kodu, zalewając konsolę błędami. | Zatrzymuje się naturalnie. Nieprzechwycony wyjątek uniemożliwia zaplanowanie kolejnego |
Potencjał wycieku pamięci | Tak, jeśli domknięcie przetrzymuje niepotrzebne referencje, a clearInterval nie zostanie wywołany. | Tak, jeśli domknięcie przetrzymuje niepotrzebne referencje, a pętla nie zostanie przerwana. |
Nie ma zatem jednej słusznej odpowiedzi. Warto znać więcej możliwości i wiedzieć jakie są ich mocne i słabe strony. Dzięki temu będziemy mogli dobrać odpowiednie narzędzie do rozwiązywanego zadania.




