
Wojciech Rygorowicz
Software Engineer

Programowanie w obliczu rewolucji AI
Data publikacji: 15.06.2026

Jeden język czy wiele? Strategie budowania stacku technologicznego
Data publikacji: 27.03.2026

setTimeout, setInterval i problemy z precyzją
Data publikacji: 17.12.2025

Losowość w programowaniu. Czy Math.random zawsze wystarczy?
Data publikacji: 11.11.2025

Nowości w ECMAScript 2025
Data publikacji: 01.10.2025

8 książek, które powinien przeczytać każdy programista
Data publikacji: 19.08.2025

Optymalizacja Wywołań Ogonowych w JavaScript
Data publikacji: 03.07.2025

Drzewa we frontendzie
Data publikacji: 16.06.2025

Czy czas frameworków dobiega końca?
Data publikacji: 30.01.2025

Web Workers - namiastka wielowątkowości we frontendzie
Data publikacji: 08.01.2025

Nowości i zmiany w React 19
Data publikacji: 15.10.2024
Komponenty Serwerowe w React
Data publikacji: 17.09.2024

Web Components - modularność, reużywalność i hermetyzacja
Data publikacji: 20.08.2024

7 książek dla początkującego programisty frontend
Data publikacji: 13.05.2024

Core Web Vitals - co to jest?
Data publikacji: 22.04.2024

Specyfikacja ES2024 - nowości w JavaScript
Data publikacji: 01.04.2024

Zanieczyszczenie prototypu
Data publikacji: 13.03.2024

CSR | SSG | SSR | RSC - czyli różne sposoby renderowania
Data publikacji: 28.01.2024

React - kompozycja komponentów
Data publikacji: 29.12.2023

JavaScript - domknięcia
Data publikacji: 27.11.2023

TypeScript - enum
Data publikacji: 12.11.2023

Obiekty Proxy i Reflect
Data publikacji: 29.10.2023

Bubbling i Capturing
Data publikacji: 18.10.2023

TypeScript - typy warunkowe
Data publikacji: 09.10.2023

Symbole w JavaScript
Data publikacji: 01.10.2023

Try, catch, finally - obsługa błędów w JavaScript
Data publikacji: 17.09.2023

TypeScript - branding i typy nominalne
Data publikacji: 10.09.2023

Destrukturyzacja w JavaScript
Data publikacji: 03.09.2023

TypeScript - typy mapowane
Data publikacji: 10.08.2023

TypeScript - typy generyczne
Data publikacji: 31.07.2023

Unknown vs Any. Czym się od siebie różnią?
Data publikacji: 19.07.2023

TypeScript - typeguard, czyli "strażnik" typu
Data publikacji: 02.07.2023

Tworzenie własnych snippetów w Visual Studio Code
Data publikacji: 09.06.2023

TypeScript - typy zaawansowane
Data publikacji: 21.05.2023

TypeScript - typy podstawowe i inferencja
Data publikacji: 05.05.2023

Typescript - jak działa i po co nam to?
Data publikacji: 17.04.2023

Wybór i konfiguracja edytora kodu
Data publikacji: 03.07.2022
Ankieta State of CSS 2026 jest już otwarta.
To idealna okazja, żeby wyrazić swoje zdanie na temat obecnej kondycji CSS, poznać najnowsze zmiany i nadrobić ewentualne zaległości technologiczne.
W końcu opublikowano wyniki ankiety State of Web Dev AI.
To świetna okazja do odkrycia nowych rozwiązań i potencjalnego odświeżenia własnego stacku technologicznego i narzędziowego. Przy okazji dowiesz się jak inni wykorzystują AI w codziennej pracy i z jakimi problemami się zmagają.
Pełne wyniki znajdziesz tutaj.
Większość z nas prawdopodobnie kojarzy ankiety State of JS czy State of React.
Ale czy wiedzieliście, że obecnie otwarta jest również ankieta State of AI?
Jej celem jest dokładne zmapowanie tego, jak wdrażamy sztuczną inteligencję do naszej codziennej pracy. Ma to pomóc w oddzieleniu realnej użyteczności tych narzędzi od wszechobecnego szumu medialnego.
Wartościowe wnioski płynące z takich badań zależą jednak od jakości danych, na których się opierają. Im więcej programistów i programistek weźmie w nich udział i podzieli się swoimi rzeczywistymi doświadczeniami, tym bardziej precyzyjne będą końcowe wyniki, z których wszyscy będziemy korzystać.
Ankietę znajdziecie tutaj.
Kilka dni temu konto jednego z deweloperów odpowiedzialnych za utrzymanie popularnej biblioteki Axios zostało przejęte. W wyniku tego ataku w repozytorium NPM opublikowano zainfekowane wersje biblioteki: 1.14.1 oraz 0.30.4. Złośliwy kod (malware) został wstrzyknięty bezpośrednio do plików wykonywalnych, co mogło prowadzić do kradzieży danych wrażliwych lub przejęcia kontroli nad środowiskiem uruchomieniowym aplikacji korzystających z tych wydań.
Jeśli zarządzasz projektami opartymi na Node.js, powinieneś niezwłocznie zweryfikować używane wersje zależności. Za pomocą poniższych komend możesz sprawdzić, czy problem dotyczy Twojego projektu:
shell
skopiuj kod
# npm
grep -E '"axios"' package-lock.json | grep -E '1\.14\.1|0\.30\.4'
shell
skopiuj kod
# yarn
grep -E 'axios@' yarn.lock | grep -E '1\.14\.1|0\.30\.4'
shell
skopiuj kod
# bun (text lockfile, v1.1+)
grep -E 'axios' bun.lock | grep -E '1\.14\.1|0\.30\.4'
Sprawdź również, czy nie została zainstalowana złośliwa biblioteka
shell
skopiuj kod
npm ls plain-crypto-js
lub
shell
skopiuj kod
find node_modules -name "plain-crypto-js" -type d
Wczoraj doszło do wycieku kodu źródłowego jednego z najnowszych narzędzi od Anthropic - Claude Code. Incydent był wynikiem błędu przy publikacji paczki w publicznym rejestrze NPM. Do biblioteki dołączono plik source mapy, który zawierał kompletny, czytelny kod źródłowy narzędzia, obejmujący ponad 500 tysięcy linii kodu w języku TypeScript.
Anthropic podjął natychmiastowe działania w celu ograniczenia skutków wycieku, wysyłając żądania usunięcia kopii kodu na podstawie przepisów DMCA (Digital Millennium Copyright Act). Mimo to, w sieci zdążyły pojawić się już oparte na wycieku projekty - jeden z użytkowników zdążył nawet przepisać logikę narzędzia na język Python i udostępnić ją w serwisie GitHub.
Czy ten incydent pozwala na darmowe korzystanie z możliwości Claude Code? Odpowiedź brzmi: nie. Wyciek dotyczy wyłącznie warstwy klienckiej i logiki operacyjnej narzędzia (tzw. agenta). Sam model językowy, który odpowiada za generowanie odpowiedzi i analizę kodu, nadal znajduje się na serwerach Anthropic i nie był częścią wycieku.
Mimo to, analiza upublicznionego repozytorium stanowi ciekawą lekturę dla programistów. Można w nim znaleźć zaawansowane techniki prompt engineeringu, specyficzne optymalizacje pracy agenta AI oraz wzmianki o funkcjonalnościach, które Anthropic planuje wdrożyć w przyszłości.
Poprzednim razem pisałem o wykinach ankiety State of JS 2025. Tym razem opublikowane został wyniki z innej, równie ciekawej ankiety - State of React 2025.
Pełny raport znajdziecie tutaj: https://2025.stateofreact.com/en-US
Wyniki State of JS 2025 zostały oficjalnie opublikowane.
Nie dość, że dają one wgląd w to, w jakim kierunku ewoluuje nasz ekosystem, to na dodatek jest to również świetny drogowskaz, który pomoże Ci określić, na czym warto skupić swój rozwój w nadchodzącym roku.
Pełny raport znajdziesz tutaj: https://2025.stateofjs.com/en-US
Od wersji 144 Chrome oferuje pełne wsparcie dla obiektu Temporal. To nowoczesny i znacznie bardziej funkcjonalny następca systemowego obiektu Date, mający rozwiązać odwieczne problemy z obsługą czasu i stref czasowych w JavaScript.
Niestety, na powszechne wdrożenie przyjdzie nam jeszcze chwilę zaczekać. Obecnie Chrome i Firefox to jedyne główne przeglądarki wspierające to rozwiązanie, dlatego zalecam wstrzymanie się z używaniem Temporal w środowisku produkcyjnym do momentu, aż obsługa API na rynku osiągnie zadowalający poziom.
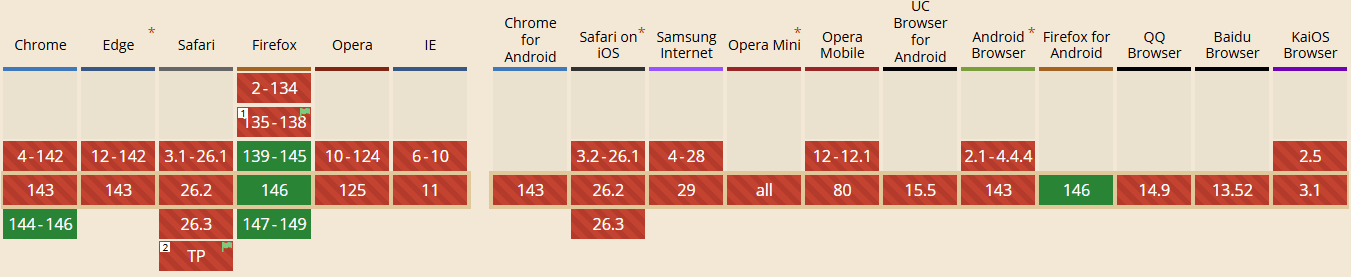
Wsparcie Temporal w różnych przeglądarkach (Styczeń 2026).
Od wersji 24.12.0 Node.js wspiera TypeScript natywnie, co eliminuje konieczność wcześniejszej kompilacji!
To usprawnienie jest szczególnie przydatne podczas szybkiego prototypowania, testowania nowych rozwiązań czy implementacji prostych serwisów, które nie wymagają skomplikowanych narzędzi do budowania.
Wystarczy uruchomić kod poleceniem: node nazwaPliku.ts
To wszystko! Kod napisany w TS może być teraz interpretowany bezpośrednio przez środowisko Node.js (warto jedynie pamiętać, że mechanizm ten opiera się na tzw. type strippingu, więc nie zastępuje walidacji typów).
Wyniki tegorocznej ankiety State of HTML są już dostępne!
Pełne zestawienie danych znajdziecie tutaj: https://2025.stateofhtml.com/en-US/
Ankieta State of React 2025 jest już oficjalnie otwarta.
Jak co roku, jest to doskonała okazja, aby mieć realny wpływ na przyszły kształt całego ekosystemu. To znacznie więcej niż zwykły kwestionariusz – to najbardziej miarodajny sposób na zweryfikowanie, co faktycznie sprawdza się w środowisku produkcyjnym, a co jest jedynie zbędnym szumem.
Tegoroczna edycja zapowiada się szczególnie ciekawie. Wraz z premierą React 19 i wyraźnym zwrotem w stronę Server Components, krajobraz naszej pracy uległ znaczącym zmianom.
Rodzi się więc pytanie: czy nowe funkcjonalności rzeczywiście rozwiązują realne problemy biznesowe, czy może tylko dokładają niepotrzebnej złożoności? To idealny moment, aby udzielić opartego na konkretnych danych feedbacku i wskazać wyzwania, z którymi zmagasz się każdego dnia.
Ankietę znajdziesz tutaj: https://survey.devographics.com/en-US/survey/state-of-react/2025?source=html2025_announcement
Kilka dni temu Anthropic, firma znana szerzej m.in. z narzędzia Claude Code, ogłosiła przejęcie Bun – bezpośredniego konkurenta Node.js i jednego z najpopularniejszych środowisk uruchomieniowych JavaScript.
Co to może oznaczać w praktyce dla świata JS?
Przede wszystkim mamy niemal gwarancję, że Bun będzie dalej rozwijany i utrzymywany. To stabilne zaplecze może sprawić, że zacznie on być częściej wykorzystywany w aplikacjach produkcyjnych.
Warto dodać, że Claude Code już wcześniej działał w oparciu o tę technologię, co było jednym z głównych powodów akwizycji. Oczywiście kontrola sprawowana przez jedną korporację rodzi pewne obawy – rozwój projektu może zostać uzależniony od biznesowych potrzeb Anthropic. Na ten moment firma zadeklarowała jednak, że Bun pozostanie projektem Open Source (na licencji MIT), co jest dobrą wiadomością dla społeczności.
React Compiler jest już dostępny w wersji 1.0!
Wprawdzie nie jest to najświeższa informacja, a wersją 1.0 możemy cieszyć się już od ponad miesiąca, to jednak większość programistów nadal nie miała okazji przetestować w praktyce dedykowanego kompilatora do Reacta. Twórcy od dawna obiecywali rewolucję – korzystanie z React Compiler ma wyeliminować potrzebę korzystania z useMemo i useCallback, usprawnić proces kompilacji i stworzyć spójny ekosystem.
Więcej na temat najnowszej wersji przeczytasz w oficjalnym poście: https://react.dev/blog/2025/10/07/react-compiler-1
5 dni temu światło dzienne ujrzała 16 wersja Next.js. Chociaż nie wprowadza ona rewolucji, zawiera kilka interesujących nowości, którym warto się bliżej przyjrzeć.
Wszystkie zmiany i poprawki opisano na oficjalnym blogu: https://nextjs.org/blog/next-16
Po ponad dekadzie pod skrzydłami Meta (wcześniej Facebook), React i React Native wkraczają w nową erę.
Od czasu swojego publicznego wydania, React stał się potęgą z ogromną społecznością. Wychodząc temu naprzeciw, Meta przekazała zarządzanie nowo powstałej firmie React Foundation – niezależnej organizacji, której celem jest nadzór nad obiema bibliotekami.
Jaka jest więc misja fundacji?
Zgodnie z oficjalnym ogłoszeniem, jej głównym celem jest wspieranie społeczności Reacta i jego ekosystemu. Do kluczowych obowiązków należeć będą:
Utrzymanie kluczowej infrastruktury, takiej jak repozytoria GitHub i potoki CI/CD.
Organizacja oficjalnej konferencji React Conf.
Tworzenie programów i zapewnianie wsparcia finansowego dla projektów w ramach ekosystemu.
Inicjatywa jest wspierana przez jedne z największych firm w branży technologicznej. Lista członków założycieli obejmuje Amazon, Callstack, Expo, Meta, Microsoft, Software Mansion i Vercel, co sygnalizuje szerokie poparcie branży dla tego nowego rozdziału.
Równolegle z fundacją powstaje nowa, niezależna struktura zarządzania technicznego. Jest to kluczowy krok, który ma na celu zapewnienie, że przyszły rozwój Reacta będzie kierowany przez kluczowych kontrybutorów i potrzeby społeczności, a nie przez interesy pojedynczej firmy.
Wystartowała ankieta State of JS 2025!
To świetna okazja, aby porównać swoją wiedzę z aktualnymi trendami i zobaczyć, co nowego dzieje się w ekosystemie JavaScript.
Twój udział pomaga również w stworzeniu obrazu branży, z którego korzysta cała społeczność - wyniki zeszłorocznej ankiety możesz zobaczyć tutaj)
Ankietę można wypełnić tutaj: https://survey.devographics.com/pl-PL/survey/state-of-js/2025
Wyniki ostatniej ankiety State of CSS są już dostępne.
Jeśli interesują Cię obecne trendy i stopień adaptacji nowych funkcji, to zdecydowanie warto tam zajrzeć.
Pełny raport znajdziesz tutaj: https://2025.stateofcss.com/en-US/
Luka pomiędzy tym, co zostało "powiedziane", a tym, co zostało "usłyszane", jest miejscem, w którym rodzą się kosztowne nieporozumienia.
Różnica ta jest jeszcze bardziej widoczna w zespołach rozproszonych po całym świecie. Kiedy mieszają się różne kultury, style komunikacji i zwyczaje, potencjał do błędnej interpretacji rośnie wykładniczo.
Niektóre kultury cenią sobie bezpośrednią, jasną komunikację, podczas gdy inne w dużej mierze polegają na czytaniu między wierszami. Sprawdza się to dobrze, gdy wszyscy dzielą ten sam kontekst kulturowy, ale w globalnym zespole jest to przepis na chaos. Istnieje wysokie prawdopodobieństwo, że jeśli nie wyrazisz czegoś wprost, Twój kolega lub koleżanka z innej części świata nie zrozumie intencji.
Dlaczego? Ponieważ nie jest on wyczulony na niuanse Twojej kultury. Nie zrozumie, że zdanie: “To będzie spore wyzwanie”, może w rzeczywistości oznaczać: “Ten termin jest niemożliwy do dotrzymania i musimy przemyśleć plan na nowo”.
Aby zniwelować tę przepaść, najskuteczniejszym krokiem jest ustanowienie prostej zasady: mów wprost. Promuj kulturę zespołową, w której każdy mówi to, co ma na myśli, nie pozostawiając kluczowych informacji między wierszami i w sferze domysłów.
Kluczowe jest, aby odpowiednio tę zasadę przedstawić. Musi być jasne, że bezpośredniość nie jest atakiem ani obrazą, a raczej sposobem na eliminowania niejasności. Gdy osoba z kultury o bardzo bezpośredniej komunikacji (np. holenderskiej) wchodzi w interakcję z kimś z kultury bardziej pośredniej (np. japońskiej), styl tej pierwszej może być postrzegany jako agresywny. Ustanawiając jawną normę zespołową, tworzysz wspólne zrozumienie, że to właśnie klarowność jest celem.
Ta zmiana nie nastąpi z dnia na dzień. Zastąpienie uwarunkowań kulturowych nabywanych przez całe życie wymaga czasu i świadomego wysiłku. I chociaż bezpośrednia komunikacja nie jest złotym środkiem na każde wyzwanie projektowe, stanowi fundamentalny krok w kierunku budowania bardziej spójnego i efektywnego globalnego zespołu.
Więcej na ten temat znajdziesz w książce Mapa Kulturowa.
Od kilku dni mamy możliwość wypełnienia ankiety State of HTML 2025.
Udział w niej, to świetna okazja, żeby wyrazić swoje zdanie w temaice standardów webowych. Przy okazji, jest to również dobry sposób na sprawdzenie własnej wiedzy, poznanie aktualnych trendów i uzupełnienie ewentualnych braków w znajomości najnowszych zagadanień.
Ankietę znajdziesz tutaj: https://survey.devographics.com/en-US/survey/state-of-html/2025
Konstrukcja try...catch...finally jest kluczowa w obsłudze błędów w JavaScript. Kryje jednak w sobie subtelną pułapkę, która może prowadzić do wyjątkowo mylących błędów.
W czym konkretnie tkwi problem? W umieszczeniu instrukcji return lub throw wewnątrz bloku finally.
Użycie ich w tym miejscu nadpisze każdą instrukcję return oraz throw z bloków try i catch. Może to prowadzić do niezwykle mylącego zachowania i trudnych do zlokalizowania błędów. Taki kod jest szczególnie niebezpieczny, gdy nie pracujemy sami – inni członkowie zespołu mogą spędzić długie godziny na debugowaniu, jeśli nie są zaznajomieni z tą specyficzną właściwością.
Wniosek? Należy unikać umieszczania return lub throw w bloku finally. Jeśli czujesz taką potrzebę, może to być oznaką większego problemu z architekturą Twojego kodu. W rzadkich przypadkach, gdy masz ku temu konkretny powód, dodaj czytelny komentarz, aby oszczędzić zespołowi przyszłych problemów.
Kilka dni temu Amazon przedstawił swoje nowe IDE - Kiro. Dodał przy tym, że jest to rewolucja. Czy faktycznie nią jest?
Pod spodem napędza je model Claude Sonnet. To Rodzi natychmiastowe pytanie: co odróżnia to narzędzie od istniejącego od jakiegoś czasu agenta Claude Code?
Amazon twierdzi, że jest to przede wszystkim podejście, które określa jako „spec-driven development”. Idea polega na prowadzeniu agenta poprzez tworzenie plików markdown, które opisują projekt, wymagania i zadania. Jeśli ten proces brzmi znajomo, to dlatego, że bardzo przypomina przepływ pracy, który wielu programistów już stosuje, korzystając z istniejących asystentów AI.
Kiro jest zatem kolejnym forkiem Visual Studio Code o zamkniętym kodzie źródłowym, który obiecuje rewolucję w sposobie tworzenia oprogramowania. Jednak jego podstawowa metodologia nie wydaje się być zupełnie nowym paradygmatem, a raczej rozwinięciem tego, co oferują nam istniejące narzędzia. Powiedziałbym raczej, że to ewolucja, a nie rewolucja.
Nie zmienia to faktu, że początkowe zainteresowanie było tak duże, że Amazon wstrzymał możliwość pobierania i wprowadził listę oczekujących.
Oficjalną stronę projektu oraz wspomnianą listę, znajdziesz tutaj: https://kiro.dev/
W świecie programowania zawsze jest jakaś biblioteka lub framework, której obsługi można się nauczyć. Pytanie tylko, faktycznie jest to tego warte?
Napływ nowych frameworków JavaScript był w pewnym momencie tak duży, że doczekał się swojego własnego mema. W połączeniu z obecnym wyścigiem AI, w którym nowe technologie i rozwiązania pojawiają się niemal z dnia na dzień, próba jakiegokolwiek nadążania za tym wszystkim jest po prostu niemożliwa.

Taki stan rzeczy rodzi nieustanny dylemat: czy powinniśmy gonić za nowościami, czy raczej pogłębiać wiedzę o tym, co już znamy i wykorzystujemy na co dzień?
Niestety nie ma to pytanie jednej, uniwersalnej odpowiedzi, a wiele zależy od Twojej obecnej roli, przyszłych celów i planu rozwoju kariery.
Dla architektów oprogramowania, posiadanie szerokiej wiedzy na temat aktualnych trendów technologicznych jest kluczowe - pomaga podejmować świadome decyzje i wybierać najlepsze narzędzia do danego zadania. Zatem w tym przypadku uzasadnione jest podejście polegające na powierzchownej nauce wielu różnych technologii i nie zagłębianie się w żadną z nich (przynajmniej, do czasu wyboru).
Jednak dla większości programistów, lepszym pomysłem będzie skupienie się na fundamentach: wybranym języku programowania, strukturach danych, algorytmach, architekturze oprogramowania, działaniu komputera itd.. Dogłębne zrozumienie języka programowania oraz wzorców projektowych, znacznie ułatwia naukę każdej nowej biblioteki czy frameworka, gdy faktycznie zajdzie taka potrzeba.
Czy to oznacza, że należy ignorować nowości? W żadnym wypadku. Istnieje jednak różnica między byciem świadomym pojawiających się trendów a odczuwaniem presji, by opanować każdy z nich do perfekcji. Owszem, można w ten sposób przegapić szansę na bycie jednym z pierwszych użytkowników kolejnego Reacta, ale znacznie bardziej prawdopodobne jest, że nowa technologia po prostu się nie przyjmie, a po kilku miesiącach zostanie niemal całkowicie zapomniana.
Na koniec krótka rekomendacja: jeżeli Twoja obecna praca nie wymaga od Ciebie poznania całego wachlarza bibliotek i frameworków, to powinieneś, lub powinnaś skupić się na ogólnych zagadnieniach związanych z programowaniem i Twoją dziedziną, a także na języku z którego korzystasz. Dogłębne zrozumienie kluczowych koncepcji przyniesie Ci znacznie więcej korzyści w dłuższej perspektywie niż powierzchowna znajomość kilkunastu przemijających trendów.
Dobrym punktem startowym dla programisty frontend, będą książki, które wymieniłem w tym artykule.
Kent Beck, twórca programowania ekstremalnego (XP), powiedział kiedyś:
W tłumaczeniu na język polski, brzmi to mniej więcej tak: “Dane z jednej iteracji są warte miesięcy spekulacji”. Ale co to właściwie oznacza?
Idea jest prosta. Zamiast spędzać miesiące na szczegółowym planowaniu, często lepiej jest zbudować wersję MVP (ang. Minimum Viable Product) i zacząć zbierać dane „w terenie” od rzeczywistych użytkowników. Pozwala to zrozumieć, czego naprawdę potrzebują nasi klienci, zamiast tylko spekulować.
Nie tak dawno temu podejście BDUF (ang. Big Design Up Front), czyli szczegółowe, wielomiesięczne projektowanie przed rozpoczęciem jakichkolwiek prac programistycznych, było dość powszechne. Zespoły spędzały znaczną ilość czasu na początkowym planowaniu, w zasadzie zgadując preferencje użytkowników i projektując funkcjonalności, które w praktyce mogły okazać się zupełnie nieprzydatne.
To z kolei płynnie łączy się z filozofią “fail fast” (szybkiego ponoszenia porażki), czyli gotowością do porzucenia pomysłu, jeżeli ten nie spełnia fundamentalnych założeń, a jego dalszy development pociągnie za sobą dodatkowe koszty, nie dając jednocześnie pewności na poprawę sytuacji.
Oczywiście nie chodzi o to, by rezygnować z projektu, gdy tylko natrafimy na pierwsze problemy. Podejście “fail fast” ma raczej na celu zachęcić do szybkiego implementowania podstawowych funkcjonalności, a następnie sprawdzenia ich w praktyce z wykorzystaniem realnych użytkowników. Kluczowe jest oczywiście zbieranie danych oraz informacji zwrotnych od klientów - na ich podstawie będziemy usprawniać produkt i dodawać nowe funkcjonalności. Na tym jednak “fail fast” się nie kończy. Jeżeli produkt nie spełnia oczekiwań i założeń biznesowych, to może się okazać, że zamiast próbować ratować coś, co nie działa, lepiej jest rozpocząć od nowa z nową perspektywą.
Takie podejście jest szczególnie istotne w przypadku startupów, projektów osobistych i małych firm. Spędzanie miesięcy na planowaniu projektu, który może nigdy nie ujrzeć światła dziennego, jest po prostu stratą czasu. Jeżeli podstawowe założenia i koncepcja, nie spotka się z pozytywnym odbiorem użytkowników, to wszelkie dodatkowe funkcjonalności i plany są bez znaczenia.
Oczywiście pewien stopień planowania jest nadal konieczny, jednak nacisk należy położyć na zdefiniowanie podstawowej wartości dla użytkownika. Kolejny krok to zbudowanie i wypuszczenie minimalnej wersji aplikacji. Jeżeli produkt się przyjmie, to przechodzimy do kolejnej iteracji i powtarzamy cały proces - planujemy (jednak tym razem na podstawie produkcyjnych danych), a następnie implementujemy kolejne funkcjonalności.
Jeżeli jednak projekt nie spełnia podstawowych założeń, to udało się uniknąć zainwestowania ogromnej ilości czasu w planowanie na wstępie. Takie podejścia pozwala szybko “ponieść porażkę” i przejść do następnego pomysłu, bogatszym w zdobytą wiedzę.
Uwaga na koniec: “fail fast” nie jest panaceum na każdy projekt. W przypadku systemów wielkoskalowych, gdzie bezpieczeństwo i ochrona są najważniejsze (banki, instytucje przetwarzające wrażliwe dane), obszerne planowanie wstępne pozostaje kluczowe. Tego typu projekty są zazwyczaj realizowane przez ugruntowane firmy z niemal nielimitowanymi budżetami. Jednak w przypadku większości startupów i nowych przedsięwzięć mentalności „fail fast” może być tym, co uchroni Twój projekt przed porażką.
Co prawda nie istnieje jedna magiczna liczba członków, do której powinny dążyć wszystkie zespoły, a wiele zależy od tego, czym dany zespół się zajmuje i w jakim obszarze działa. Istnieje jednak zasada "dwóch pizz", która może stanowić rodzaj drogowskazu. Reguła jest prosta: jeśli zespół jest zbyt duży, by najeść się dwiema pizzami, to istnieje ryzyko, że jego wydajność nie jest tak dobra, jak być powinna. Głównym winowajcą jest nadmiar komunikacji.
Ta prosta heurystyka podkreśla kluczową kwestię: mniejsze zespoły często pracują wydajniej.
Pomyśl o ostatnim projekcie, nad którym pracowałeś/aś sam(a). Koszt komunikacji jest zerowy. Nie musisz nikogo prosić o opinię, synchronizować pracy, ani czekać na design. Pozwala to poświęcić 100% czasu na “prawdziwą” pracę.
Dodajmy teraz do tego jednoosobowego zespołu kolejną osobę. Natychmiast pojawia się potrzeba komunikacji, koordynacji zadań i uzgadniania celów. Niewielka część czasu każdej osoby jest teraz przeznaczona na coś innego niż jej główne zadania. Całkowita wydajność zespołu rośnie, ale czas, który każdy może poświęcić na pracę w pełnym skupieniu, nieznacznie się zmniejsza.
Gdy dodasz trzecią osobę, narzut komunikacyjny nie rośnie liniowo. Rośnie wykładniczo - każdy dotychczasowy członek ma teraz kolejną osobę, z którą musi się synchronizować. Czas spędzony na uzgodnieniach wzrasta, a indywidualna produktywność spada jeszcze bardziej.
Istnieje punkt krytyczny, w którym narzut komunikacyjny staje się tak duży, że wydajność zespołu faktycznie zaczyna spadać. Więcej czasu spędza się na spotkaniach, czytaniu e-maili i ustalaniu wspólnej wizji niż na osiąganiu wymiernych postępów. Świetnie obrazuje to tabela z książki “The Art of Scalability”:
Wielkość zespołu | Koszt komunikacji i koordynacji | Indywidualna produktywność | Produktywność organizacji |
|---|---|---|---|
1 | 0 | 1 | 1 |
3 | 0.005 | 0.995 | 2.985 |
10 | 0.010 | 0.99 | 9.9 |
20 | 0.020 | 0.98 | 19.6 |
30 | 0.05 | 0.95 | 28.5 |
Musimy również wziąć pod uwagę ryzyko przeładowania informacjami. Gdy dostajemy zbyt wiele maili, wiadomości, i powiadomień, to z czasem zaczynamy po prostu ignorować część z nich. Założę się, że nie czytasz wszystkich maili, które dostajesz na swój prywatny adres email. Być może robisz to samo z mailami służbowymi - filtrujesz tylko to, co według Ciebie jest najważniejsze. Ryzyko, które niesie za sobą takie podejście, to oczywiście przeoczenie ważnych informacji i nieodpowiadanie na maile w akceptowalnych ramach czasowych (lub w ogóle).
Podsumowując: samo dodawanie kolejnych osób do zespołu nie zawsze jest odpowiedzią na zwiększenie jego wydajności. Koszt komunikacji to realny czynnik, a czasami mniejszy, bardziej skoncentrowany zespół, który nie jest stale rozpraszany przez czynniki zewnętrzne lub wewnętrzne, może osiągnąć znacznie więcej.
Zespół odpowiedzialny za silnik V8 wprowadził niedawno nową funkcję: Explicit Compile Hints (Jawne Wskazówki Kompilacji), która może być niezwykle przydatna, gdy wydajność aplikacji jest priorytetem.
Zacznijmy od tego, że V8 wykonuje mnóstwo optymalizacji za kulisami. Jedną z nich jest kompilowanie wybranych fragmentów kodu JS do kodu maszynowego. Do tej pory silnik opierał się jedynie na swoich przewidywaniach i wybierał kod, który skompiluje wyłącznie na podstawie wewnętrznych algorytmów.
Wraz z wprowadzeniem wskazówek kompilacji nieco się to zmienia. Możemy teraz dodawać specjalne komentarze w swoich plikach JavaScript (w przyszłości funkcjonalność będzie dostępna dla pojedynczych funkcji), aby poinformować V8, że powinien wstępnie skompilować określony kod. Oznaczenie pliku w ten sposób może znacznie zwiększyć wydajność aplikacji, zwłaszcza w przypadku kodu, który jest niezbędny podczas ładowania strony.
W czym może pomóc nam poprawne oznaczenie kluczowych plików JavaScript?
Zapobiega blokowaniu głównego wątku: Zazwyczaj, jeśli funkcja nie została jeszcze skompilowana, musi zostać skompilowana „na żądanie” przy pierwszym wywołaniu. Ten krok kompilacji musi nastąpić przed wykonaniem funkcji. W efekcie wątek główny musi “zaczekać” na wynik kompilacji, co może prowadzić do powolnego działania interfejsu użytkownika.
Poprawia czasy ładowania: Wstępna kompilacji kluczowych funkcji jest wykonywana w tle i nie blokuje głównego wątku. Jest to szczególnie ważne w przypadku funkcji wywoływanych podczas pierwszego ładowania strony. Szybsze wczytanie strony może zadecydować, czy użytkownik postanowi na niej zostać, a to z kolei przekłada się bezpośrednio na wyniki finansowe. Dodatkowo, szybsze wczytywanie strony może mieć pozytywny wpływ na SEO.
Jak w takim razie dać znać silnikowi, że powinien dokonać pre kompilacji całego pliku? Wystarczy umieścić odpowiedni komentarz na samej górze kodu.
Tak jak w każdym przypadku, tak i tutaj trzeba jednak zachować umiar. Kompilowanie zbyt dużej ilości kodu z góry zużyje czas i pamięć, co może przynieść odwrotny skutek i spowolnić działanie. Należy skupić się jedynie na krytycznym kodzie, który jest wykonywany natychmiast po wejściu użytkownika na stronę. Warto także monitorować wydajność przed oraz po wprowadzeniu zmian.
Połączenie operatora keyof oraz typu any może na pierwszy rzut oka wyglądać dziwnie. Skoro any reprezentuje dowolny typ, to co właściwie jest jego kluczami?
Okazuję się, że wynikiem zestawienia tych dwóch słów jest unia typów: string | number | symbol. Jeżeli chwilę się nad tym zastanowimy, to dojdziemy do wniosku, że są to typy, które mogą zostać użyte jako klucze w obiekcie w JavaScript oraz TypeScript.
A zatem keyof any zwraca unię typów, które bezpiecznie możemy zastosować jako klucze obiektu. Kiedy może się to okazać przydatne?
jako ograniczenie typu generycznego (artykuł na temat typów generycznych znajdziesz tutaj)
podczas tworzenia typu opisującego dowolny obiekt (typ mapowany, który zastosowałem w przykładzie szerzej opisuję w tym artykule)
do opisania tablicy, która pasuje do metody
Object.fromEntries()
Zastosowań jest wiele, a te które wymieniłem, z pewnością nie wyczerpują tematu.
Każda dziedzina ma swoje niepisane zasady, a programowanie nie jest wyjątkiem.
Prawo Hyruma można zaobserwować w działaniu w całym krajobrazie technologicznym. Nie ma znaczenia, czy pracujesz z Unity, tworzysz frontend, czy rozwijasz systemy backendowe – ta zasada ma zastosowanie wszędzie.
Czym więc dokładnie jest?
Stworzone przez Hyruma Wrighta prawo brzmi:
W gruncie rzeczy, gdy twoje API zyska wystarczającą popularność, każde obserwowalne zachowanie – nawet jeśli nie jest częścią oficjalnego, udokumentowanego kontraktu – nieuchronnie stanie się dla kogoś zależnością. Oznacza to, że granica między „publicznym API” a „prywatnymi szczegółami implementacji” zaciera się, co prowadzi do kilku istotnych implikacji:
Zmiany w publicznym API: Ponieważ jest to oficjalny interfejs, większość użytkowników będzie polegać na jego zadeklarowanym zachowaniu. Wszelkie modyfikacje w tym obszarze muszą być skrupulatnie zaplanowane, dokładnie udokumentowane i najlepiej wersjonowane (pomyśl o Semantic Versioning), aby zapobiec niezamierzonym zmianom powodującym błędy.
Refaktoryzacja kodu wewnętrznego: Nawet zmiany w tym, co uważasz za „wewnętrzne” lub „prywatne” szczegóły implementacji, wymagają szczególnej ostrożności. Jeśli wewnętrzne zachowanie jest obserwowalne, ktoś, gdzieś, może na nim polegać. Jego zmiana może zepsuć zależne projekty – co jest szczególnie kosztownym błędem w przypadku wewnętrznych systemów firmowych, gdzie wymówka „zmieniłem tylko prywatne API!” nie przejdzie, jeśli produkcja padnie i wpłynie to na finanse firmy.
Prawo Hyruma jest, niestety, nieuniknioną rzeczywistością dla każdego oprogramowania, które jest adoptowane przez innych deweloperów. Chociaż staranna enkapsulacja i ukrywanie informacji mogą pomóc, w miarę ewolucji systemu i wzrostu jego użytkowania, niektóre zachowania nieuchronnie staną się „de facto” API dla twoich użytkowników.
Jaki jest więc kluczowy wniosek? Podchodź do każdej refaktoryzacji z ostrożnością, stosuj strategie wersjonowania i zawsze bierz pod uwagę potencjalny wpływ każdej zmiany na dalsze etapy – nawet w przypadku rzekomo „wewnętrznych” zachowań. Twoi koledzy (i wyniki finansowe twojej firmy) będą ci za to wdzięczni.