

Na początku mały disclaimer - dla zrozumienia tego, o czym będę mówił, powinieneś/powinnaś wiedzieć już jak komputery reprezentują liczby całkowite, ponieważ będę odnosił się do tej wiedzy i pojęć. Jak więc komputer radzi sobie z ułamkami? Co to są liczby zmiennoprzecinkowe? Dlaczego ich potrzebujemy? Zapraszam na głęboką analizę działania floatów ze standardu IEEE 754 - najczęstszego sposobu reprezentowania ułamków w nowoczesnych komputerach.
Ten krótki wstęp zawierał małe uproszczenie. Liczby zmiennoprzecinkowe nie są używane jedynie do ułamków, chociaż to o nich najczęściej myślimy, kiedy deklarujemy floata. Tak naprawdę to format, w którym można zapisać dowolną liczbę wymierną w formie x × 2ʸ. To oznacza, że możliwe jest w ten sposób kodowanie bardzo dużych liczb, jak i bardzo małych, bliskich 0. Zanim jednak o szczegółach, warto wiedzieć jaki problem rozwiązują liczby zmiennoprzecinkowe i co było zanim zostały ustandaryzowane jako IEEE 754.
Ułamek - źródło problemu
Każdy komputer, będąc fizyczną maszyną, ma ograniczoną ilość bitów przypadającą na liczbę. Czasem wystarczy 8, innym razem mamy dostępne 128 bitów. W przypadku liczb całkowitych sprawa jest względnie prosta. Zazwyczaj wystarczy przydzielić 32 lub 64 bity na jedną liczbę, co w zupełności wystarcza do większości zastosowań. Maksymalna liczba 32-bitowa bez znaku to ponad 4 miliardy, a 64-bitowa jest od niej ponad 4 miliardy razy większa. Procesor potrafi na nich operować poprzez wbudowane instrukcje, oddzielne dla poszczególnych rozmiarów.
W odróżnieniu od liczb całkowitych, ułamki składają się z dwóch równie ważnych części – tej przed i za przecinkiem. Szybko okazuje się, że zwykłe zamienienie każdej części na system dwójkowy i złączenie w całość mocno ograniczy zakres, który można w ten sposób reprezentować, przy użyciu tej samej ilości bitów. Każda dodatkowa cyfra z jednej strony przecinka odbiera miejsce po drugiej stronie. To tzw. liczba stałoprzecinkowa i ma ona więcej wad, niż tylko ograniczony zakres. Kilka z nich to:
architektura procesora musiałaby wspierać liczby z przecinkami w różnych miejscach
operacje na dwóch typach z przecinkiem w innym miejscu wymagałyby dodatkowych instrukcji procesora, powiększając jego fizyczny rozmiar, cenę i ogólną złożoność
precyzja takich liczb jest mniej przewidywalna
dużo wyższa trudność pisania poprawnego kodu
Nie znaczy to, że liczby stałoprzecinkowe nie mają zastosowania. Są używane w niektórych mikrokontrolerach (np. ze względu na wyższą wydajność), lub w sytuacjach, w których nie można pozwolić sobie na przybliżenia, będące nieodłącznym elementem liczb zmiennoprzecinkowych.
Odpowiedzią na te i inne problemy są właśnie floaty. Jeszcze w latach 80. każdy producent komputerów miał własny sposób na ich kodowanie, a kod skompilowany dla jednej maszyny nie mógł współpracować z inną. Zmienił to dopiero standard IEEE 754. Dzisiaj wspiera go niemal każdy komputer i to właśnie na nim się skupię.
Zasadę, na której się opierają, można sobie wyobrazić na przykładzie bardzo dużej wartości, np. 5 × 2¹⁰⁰. Jej bity to 101 i sto 0. Nie zmieszczą się one w typowym dzisiaj 64-bitowym słowie. Ta długa forma nie jest jednak konieczna, bo zapis x × 2ʸ jest zupełnie wystarczający. W dużym skrócie tak właśnie działają floaty. Dla uproszczenia, w opisywanym przykładzie będę używał wartości 8-bitowej. Pamiętaj jednak, że 8-bitowe floaty nie są oficjalnie częścią standardu IEEE 754.
Jak zakodowany jest IEEE 754 floating point?
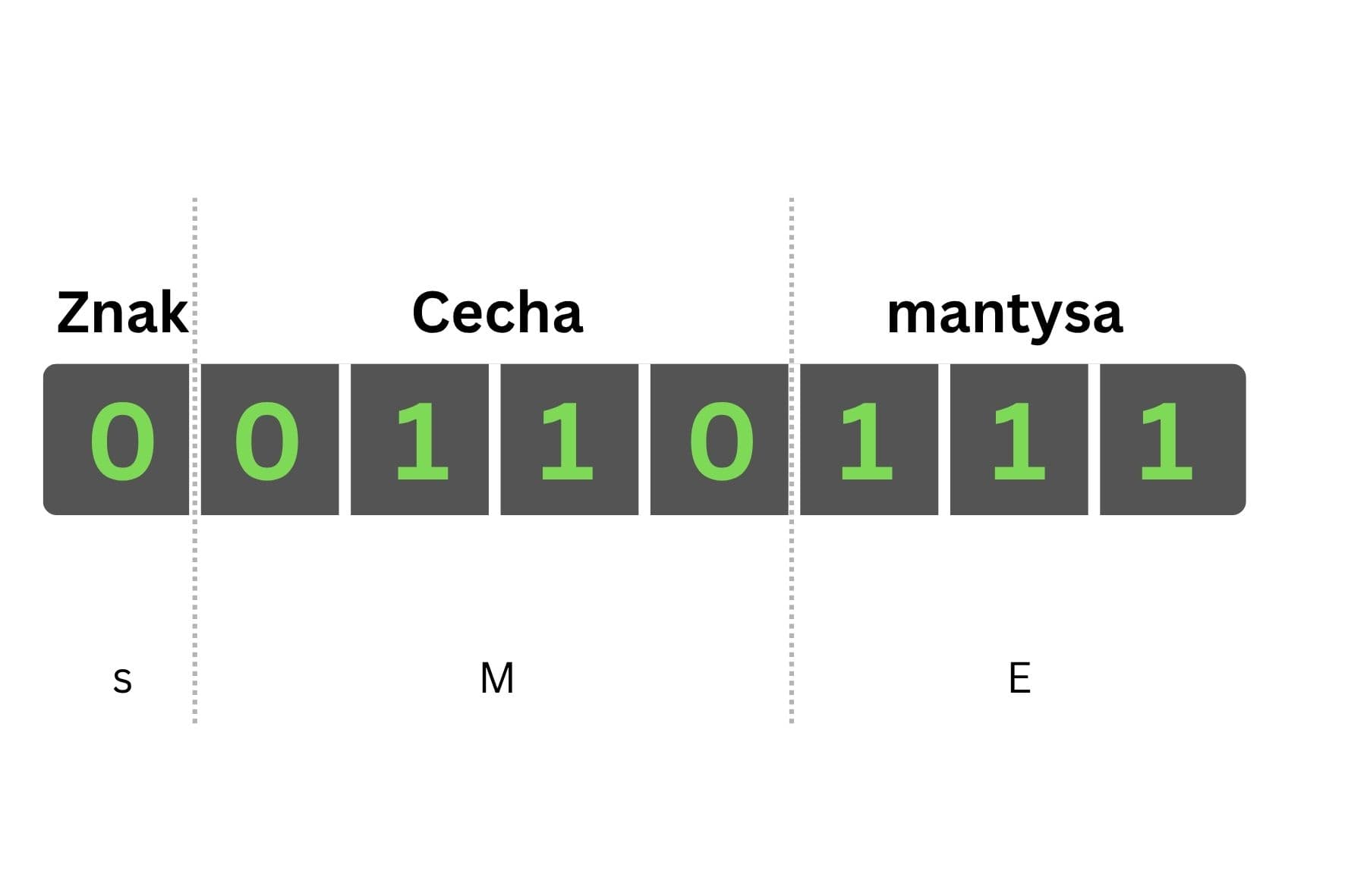
Układ bitów i ich znaczenie w liczbach zmiennoprzecinkowych
Mamy więc 3 główne części składowe: s, M, E. Przyjrzymy się im teraz bliżej. Zanim przejdziemy dalej, odsłonię jeszcze prawdziwy "wzór na floata". x × 2ʸ to tak naprawdę (-1)ˢ × M × 2ᴱ.
Patrząc od lewej strony, pierwszy bit to znak (s). Tak samo jak w liczbach całkowitych ze znakiem, 0 oznacza liczbę pozytywną, 1 negatywną. Tutaj znak wynosi 0.
Kolejne 4 bity to tzw. cecha albo wykładnik (E). W tym konkretnym przypadku można tu zapisać liczby od 0 do 15, ale sama cecha to liczba całkowita w kodzie z nadmiarem. Nadmiar oznacza, że liczba zakodowana tymi bitami jest powiększona o pewną z góry ustaloną wartość. Żeby odczytać, co przechowują te 4 bity, musimy odjąć od ich faktycznej wartości nadmiar, który dla 4-bitowej cechy wynosi 7 (można obliczyć nadmiar dla każdej długości cechy n wg. wzoru 2ⁿ⁻¹-1). Nadmiar pozwala zapisać liczbę negatywną w formie liczby bez znaku. W tym konkretnym przypadku bity 0110 wskazują na cyfrę 6, ale po odjęciu nadmiaru otrzymujemy -1. Cecha będzie negatywna zawsze, kiedy cała liczba zmiennoprzecinkowa jest mniejsza niż 1.
Potem są 3 bity tzw. mantysy (M). Mantysa to część ułamkowa, ale podobnie jak w przypadku cechy, jest tutaj zastosowana pewna sztuczka. Ponieważ w zdecydowanej większości przypadków mantysa zawiera się w zakresie od 1 ≤ x < 2, można w ogóle nie zapisywać wiodącej cyfry 1 i zyskać jeden bit precyzji (mantysa bezpośrednio wpływa na precyzję całej liczby zmiennoprzecinkowej). To pole zawiera zatem liczbę w formacie 0.xxx. Faktyczną wartość mantysy otrzymamy (najczęściej) dodając 1. Na obrazku mamy 111 = ⅞ = 0.875, a dodając 1 otrzymujemy 1.875.
Kiedy podstawimy wszystkie wartości do wzoru, otrzymujemy (-1)⁰ × 1.875 × 2⁻¹ = 0.9375. To liczba zakodowana na obrazku.
Być może zastanawiasz się, o co chodzi z tym nadmiarem cechy i dlaczego nie użyć po prostu kodu uzupełnień do 2, tak jak to zwykle bywa w liczbach całkowitych ze znakiem. Okazuje się, że jest ku temu bardzo dobry powód - łatwość porównań dwóch floatów. Możliwość zapisania cechy jako liczby bez znaku sprawia, że wartości te będą rosnące wraz z wielkością całej liczby. Kilka przykładów:
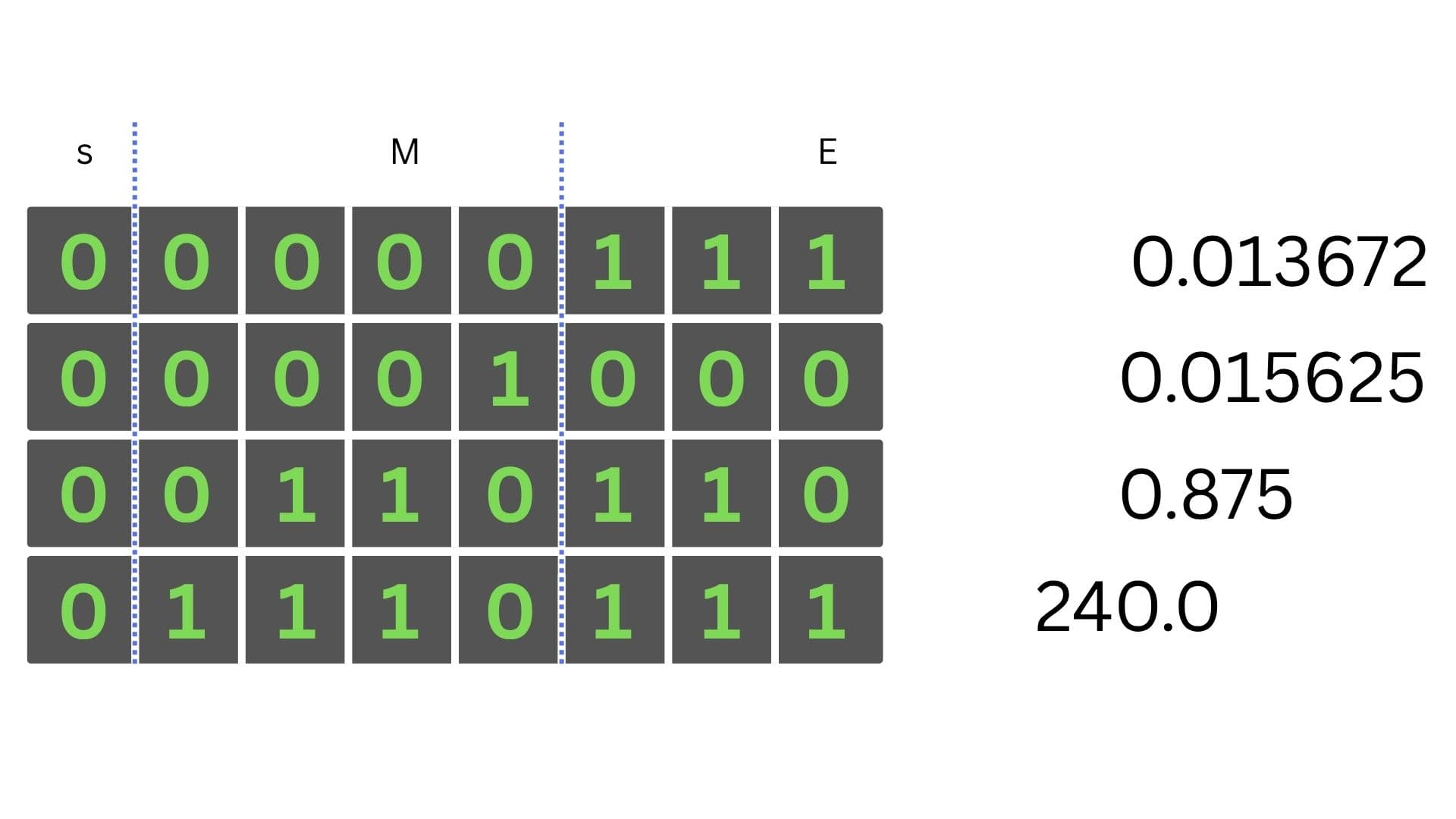
Porównanie liczb zmiennoprzecinkowych przedstawione wizualnie.
Porównanie ze sobą dwóch floatów w tej formie pozwala na użycie prostszych instrukcji procesora. Już na oko widać, która liczba jest większa. Gdyby cecha była kodowana jak typowa liczba całkowita ze znakiem, te same liczby miałyby następujące układy bitów:
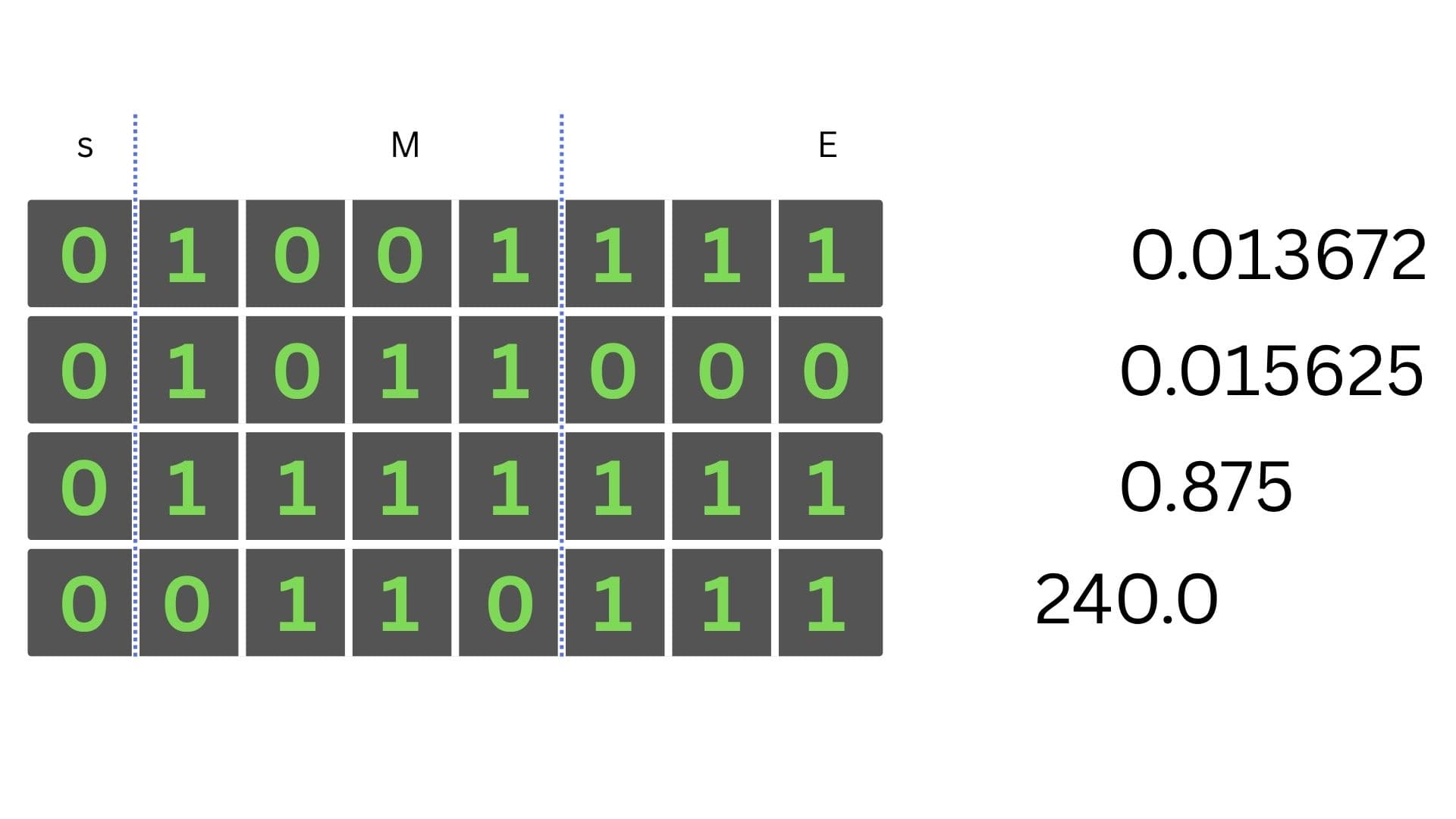
Porównanie liczb zmiennoprzecinkowych, gdyby nie były kodowane z nadmiarem.
Wszystkie przykłady, które opisałem do tej pory, miały postać znormalizowaną, tj. bity wykładnika nie są ani samymi zerami, ani jedynkami.
Wartości zdenormalizowane
Kiedy wykładnik składa się z samych zer, mówimy o postaci zdenormalizowanej. Oprócz wykładnika jest tu też drobna różnica w mantysie. Wspomniałem wcześniej, że do tego, co w niej zapisane, trzeba dodać "1", żeby ją odczytać. Dotyczyło to tylko postaci znormalizowanej. Kiedy wykładnik składa się z samych 0, nie dodajemy już jedynki do mantysy. Dzięki temu można zapisać wartości bardzo bliskie zeru, które w innym przypadku zostałyby do niego zaokrąglone. Oprócz tego liczby zdenormalizowane pozwalają na zapisanie +0.0 i -0.0 (tak, obie są przewidziane w standardzie).
Wartości specjalne
Oprócz liczb, standard IEEE 754 przewiduje jeszcze kilka wartości specjalnych: -∞, +∞ i NaN. Ich znakiem rozpoznawczym jest wykładnik składający się z samych 1. -∞ i +∞, w zależności od bitu znaku, występują kiedy mantysa to same 0. Mogą pojawić się w sytuacji przepełnienia liczby (overflow) lub dzielenia przez 0. W innym przypadku mamy do czynienia z NaN.
Ten system pozwala zapisywać nie tylko ułamki, ale i bardzo duże liczby, np. 32-bitowy floating-point może przechowywać maksymalnie 3.4028235 × 10³⁸. To ma jednak swoją cenę w postaci wspomnianych na wstępie przybliżeń, które w tak ekstremalnych przypadkach sięgają równie absurdalnych wartości. Błąd wynikający z przybliżenia dla maksymalnej 32-bitowej liczby to 3361471140188295800000000000000. O błędach przybliżeń warto pamiętać też kiedy operujemy na ułamkach, których nie da się przedstawić precyzyjnie w systemie dwójkowym, jak ⅒. To dlatego 0.1 + 0.2 == 0.30000000000000004.
Arytmetyka
To tutaj unikalny character liczb zmiennoprzecinkowych często daje o sobie znać. Oto kilka rzeczy na które warto uwazać:
Nieprzemienność i niełączność to chyba największa pułapka. Dla floatów (a + b) + c nie zawsze równa się a + (b + c). Oznacza to, że kolejność operacji ma znaczenie a kompilatory zazwyczaj nie mogą swobodnie zmieniać kolejności obliczeń.
Kumulacja blędów. W długich obliczeniach małe błędy zaokrągleń mogą narastać. Wymaga to specjalnego traktowania albo zrezygnowania z użycia floatów w szczególnych przypadkach. Jeżeli chcesz zglębić ten temat, polecam wyszukać zjawisko nazywane "catastrophic cancellation".
Standard definiuje kilka rodzajów zaokrągleń wyników (jeśli jest to konieczne). Najczęściej występujące jest zaokrąglanie do najbliższej liczby całkowitej (inne to zaokrąglenie w dół, w górę, albo w kierunku zera). Jeżeli float jest dokładnie w połowie pomiędzy dwoma liczbami całkowitymi, wybieramy wtedy liczbę parzystą. Np. 1.5 i 2.5 powinny obie zostać zaokrąglone do 2. Celem tego jest równomierne rozłożenie zaokrąglonych liczb w przypadku większego zbioru. Statystycznie, mniej więcej połowa będzie dzięki temu zaokrąglona w górę, a druga w dół. Podobna zasada obowiązuje jeżeli to ułamek wymaga zaokrąglenia w przypadku castowania większego floata do mniejszego, np. z 64 do 32 bit.
Parę słów na koniec
Skoro liczby zmiennoprzecinkowe mają zupełnie inną reprezentację niż całkowite, wymagają też osobnych instrukcji i rejestrów w architekturze procesorów. Nie wszystkie języki eksponują to w jasny sposób. W statycznie typowanych językach jesteśmy zmuszeni myśleć o liczbach całkowitych i zmiennoprzecinkowych jak o dwóch osobnych bytach, bo tym właściwie są. Inaczej jest w wysokopoziomowych językach skryptowych. Kiedy deklarujemy typ number w JS, najpewniej jest on przechowywany jako 64-bitowy float. Python, co prawda, ma osobne typy int i float, ale przy wykonywaniu np. operacji arytmetycznych na mieszanych typach, int będzie konwertowany najpierw do floata. Wymaga to dodatkowej instrukcji procesora i spowoduje zmianę bitów w przechowywanej wartości.
W nowoczesnych procesorach na floaty jest kładziony ogromny nacisk ze względu na ich użyteczność w wielu dziedzinach, takich jak:
symulacje i obliczenia naukowe
grafika 3D i renderowanie
uczenie maszynowe
Sprawdź ten interaktywny konwerter liczb zmiennoprzecinkowych, jeżeli chcesz poeksperymentować z floatami!